SDSC6007 Course 1
SDSC6007 Course 1
#sdsc6007
Introduction
The Discrete-Time Dynamic System
The system has the form
where
-
: index of discrete time
-
: the horizon or number of times control is applied
-
: the state of the system, from the set of states Sk
-
: the control/decision variable/action to be selected from the set Uk (xk ) at time k
-
: a random parameter (also called disturbance)
-
: a function that describes how the state is updated
Assumption
’s are independent. The probability distribution may depend on and .
The Cost Function
The (expected) cost has the form
where
-
: the cost incurred at time .
-
: the terminal cost incurred at the end of process.
Note
Because of , the cost is a random variable and so we are optimizing over the expectation.
A Deterministic Scheduling Problem
Example
Prof Li ZENG wants to produce luxury headphones that perform better than the bear-pods 3 that he is currently using. To do so, four operations must be performed on a certain machine, and they are denoted by A, B, C, D. Assuming that
-
operation B can only be performed after operation A
-
operation D can only be performed after operation C
Denote
-
setup cost Cmn for passing any operation m to n
-
initial startup cost SA or SC (can only start with operation A or C)
Solution
-
We need to make three decisions (the last is determined by the first three)
-
This problem is deterministic (no wk )
-
This problem has finite number of states
-
Deterministic problems with finite number of states => transition graph
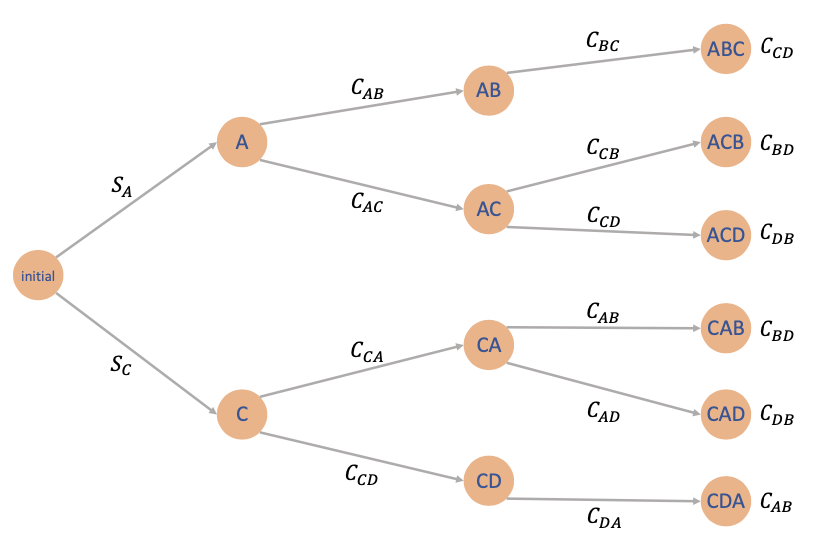
Discrete-State and Finite-State Problems
To capture the transition between states, it is often convenient to define the transition probabilities
In the dynamic system, it means that , where follows a probabilitydistribution which has probabilities 's.
Example
Consider a problem of N time periods that a machine can be in any one of n states. We denote as the operating cost per period when the machine is in state i. Assume that
That is, a machine in state i works more efficiently than a machine that is in state i + 1. During a period of time, the state of the machine can become worse or stay the same with probability
At the start of each period, we can choose
-
let the machine operate one more period
-
repair the machine and bring it to state 1 (and it will stay there for 1 period) at a cost R
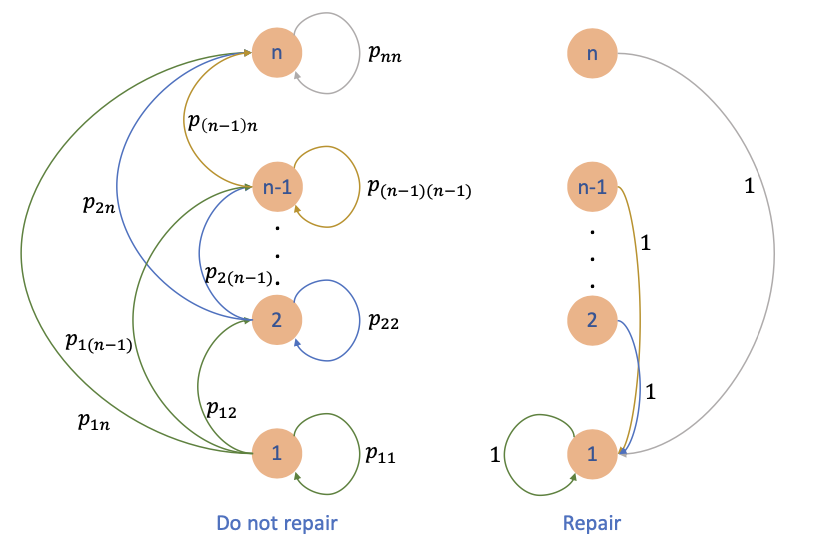
Inventory Control Problem
Ordering a quantity of a certain item at each stage to meet a stochastic demand
-
: stock available at the beginning of the kth period
-
: stock ordered and delivered at the beginning of the kth period
-
: demand during the kth period with given probability distribution
-
: penalty/cost for either positive or negative stock
-
: cost per unit ordered
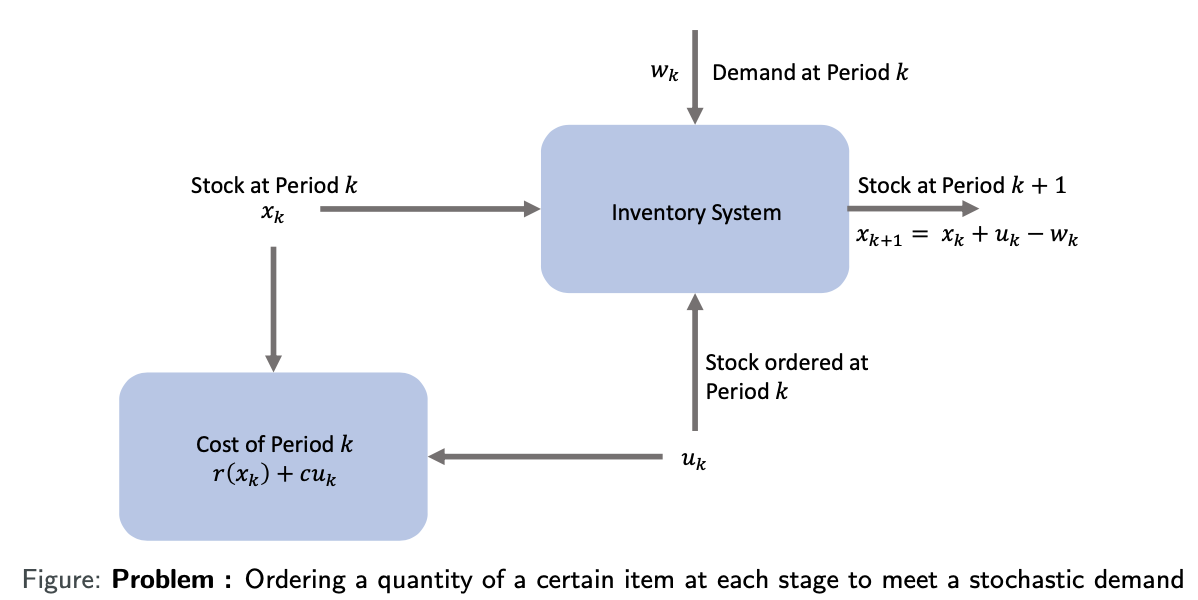
Expample: Inventory Control
Suppose is the optimal solution of
What if:? (recall wi’s are the demands.)
We can do better if we can adjust our decisions to different situations!
Open-Loop and Closed-Loop Control
Open-loop Control
At initial time , given initial state , find optimal control sequence minimizing expected total cost:
-
Key feature: Subsequent state information is NOT used to adjust control decisions
Closed-loop Control
At each time , make decisions based on current state information (e.g. ordering decision at time ):
-
Core objective: Find state feedback strategy mapping state to control
-
Decision characteristics:
-
Re-optimization at each decision point
-
Control rule designed for every possible state value
-
Computational properties:
-
Higher computational cost (requires real-time state mapping)
-
Same performance as open-loop when no uncertainty exists
Closed-loop Control
Core Concepts
-
Control Law Definition
Let be a function mapping state to control :
-
Control Policy
Define a policy as a sequence of control laws:
-
Policy Cost Function
Given initial state , the expected cost of policy is:
Admissible Policy
A policy is called admissible if and only if:
Meaning at each time and for every possible state , the control must belong to the allowable control set .
Summary
Definition
Consider a function defined as:
where:
-
: Set of all admissible policies
-
: Expected cost of policy starting from initial state
We call the optimal value function.
Key Properties
-
Global Optimality
gives the minimum possible expected cost from any initial state -
Policy Independence
Represents theoretical performance limit, independent of specific policies -
Benchmarking Role
Any admissible policy satisfies:
Computational Significance
-
Core Objective of DP: Compute exactly via backward induction
-
Control Engineering Application: Measure gap between actual policies and theoretical optimum
The Dynamic Programming Algorithm
Principle of Optimality
Theorem Statement
Let be an optimal policy for the basic problem. Suppose when using , the system reaches state at time with positive probability. Consider the subproblem starting from :
Then the truncated policy is optimal for this subproblem.
Core Implications
-
Heritability of Optimality
Any tail portion of a globally optimal policy remains optimal for its starting state -
Time Consistency
Optimal decisions account for both immediate cost and optimal future state evolution -
Foundation for Backward Induction
This principle validates the dynamic programming backward solution approach.
Practical Significance
-
Reduces Computational Complexity: Decomposes problem into nested subproblems
-
Guarantees Global Optimality: Concatenation of locally optimal decisions yields global optimum
-
Enables Real-time Decision Making: Supports receding horizon methods like MPC
