#sdsc5001
English / 中文
统计学与机器学习的术语对比
| 统计学 |
机器学习 |
| 分类/回归聚类含缺失响应的分类/回归(非线性)降维 |
监督学习无监督学习半监督学习流形学习 |
| 协变量/响应变量样本/总体统计模型误分类/预测误差 |
特征/结果训练集/测试集学习器泛化误差 |
| 多类逻辑函数截断线性函数 |
Softmax函数ReLU(线性整流单元) |
关键说明:两个领域使用不同术语描述相似概念,但核心思想相通。例如统计学的"协变量"对应机器学习的"特征"。
实际应用案例
工资预测案例
任务:理解员工工资与多个因素之间的关联关系

数据来源:基于美国大西洋地区男性员工收集的数据集
垃圾邮件检测案例
任务:构建能够自动检测垃圾邮件的过滤器
数据表示:
| 观测值 |
make% |
address% |
… |
总大写字母数 |
是否为垃圾邮件 |
| 1 |
0 |
0.64 |
… |
278 |
1(是) |
| 2 |
0.21 |
0.28 |
… |
1028 |
1(是) |
| 3 |
0 |
0 |
… |
7 |
0(否) |
| … |
… |
… |
… |
… |
… |
| 4600 |
0.3 |
0 |
… |
78 |
0(否) |
| 4601 |
0 |
0 |
… |
40 |
0(否) |
数据集特征:
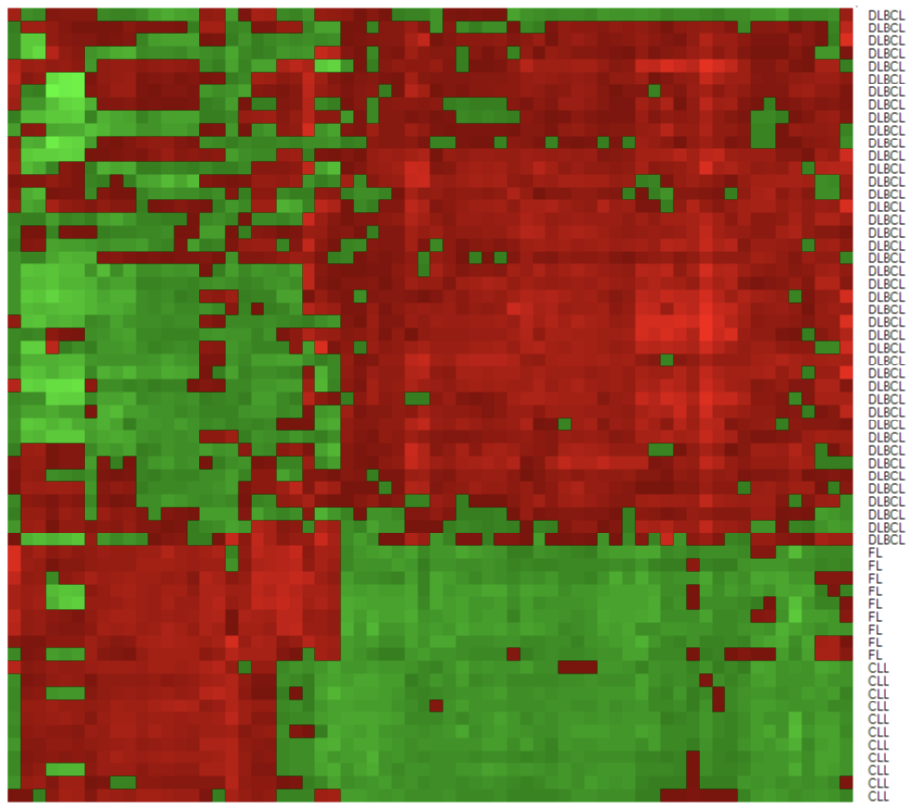
基因微阵列案例
任务:基于患者基因型自动诊断癌症
数据特征:
-
4026个基因表达谱
-
62名患者,3种成人淋巴恶性肿瘤类型
-
66个"精心"选择的基因
基本符号表示
训练样本:(xi,yi)i=1n
数据生成模型:
Y=f(X)+ϵ
-
f:未知函数,表示X提供的关于Y的系统性信息
-
ϵ:随机误差项,满足:
- 均值为零:E(ϵ)=0
- 与X独立
误差项ϵ存在的原因:
-
未测量的因素
-
测量误差
-
内在随机性
估计方法
参数模型
-
线性/多项式回归模型
-
广义线性回归模型
-
Fisher判别分析
-
逻辑回归
-
深度学习
非参数模型
-
局部平滑
-
平滑样条
-
分类回归树、随机森林、提升方法
-
支持向量机
预测与推断 (不考)
预测
基于估计函数f^,对新X预测响应:
Y=f^(X)
预测误差分解:
E(Y−Y)2=可减少误差E(f^(X)−f(X))2+不可减少误差var(ϵ)
推断
目标:理解Y如何受X影响
-
哪些预测变量与Y相关?
-
Y与每个预测变量的关系如何?
-
干预某些预测变量时Y如何变化?
预测与推断的平衡:
分类问题
分类与回归略有不同:
P(Y=k∣X)=fk(X);k=1,…,K
分类决策函数:
ϕ^(X)=kargmaxf^k(X)
误分类误差:
P(Y=ϕ^(X))=E(I(Y=ϕ^(X)))
示例:二分类玩具问题
问题描述:从未知分布模拟200个点,两个类别{蓝色, 橙色}各100个,构建预测规则
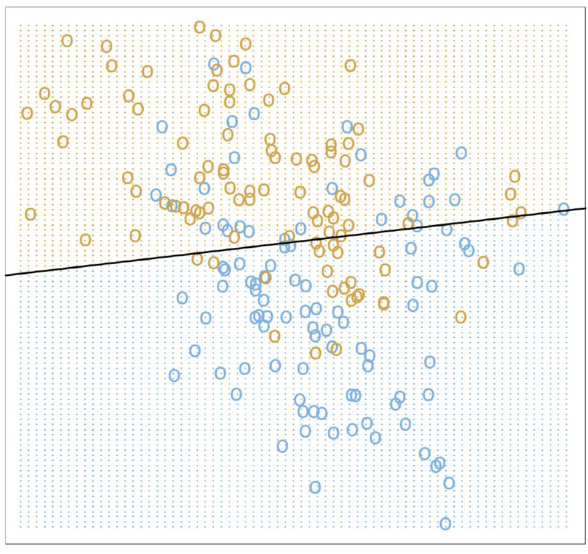
模型1:线性回归
编码:Y=1(橙色),Y=0(蓝色)
模型形式:
Y=β0+j=1∑pXjβj=Xβ
参数估计(最小二乘):
β^=(XTX)−1XTy
分类决策函数:
ϕ^(X)=I(XTβ^>0.5)
模型2:K近邻(K-NN)
基于邻居预测:
y^(X)=k1i=1∑nyiI(xi∈Nk(X))
其中Nk(X)是包含恰好k个邻居的X的邻域
分类决策函数(多数投票):
ϕ(X)=I(y(X)>0.5)
模型复杂度对比:
-
线性回归:使用3个参数
-
K-NN分类器:使用n/k个有效参数
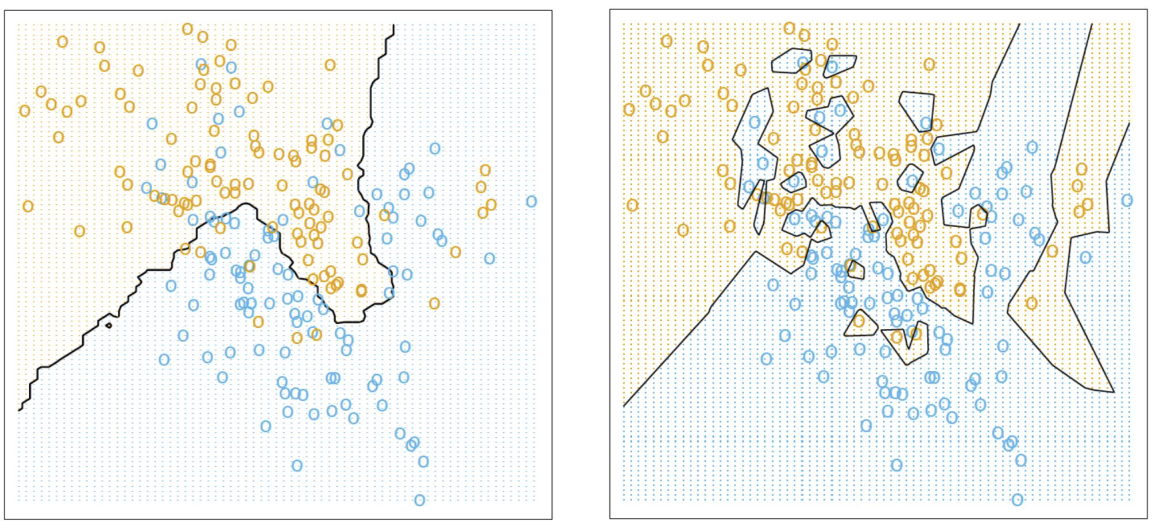
15-NN和1-NN分类结果对比图
回归模型评估
均方误差(MSE)及其最小化
均方误差(MSE)的定义
对于回归问题,其中 Y∈R 和 X∈Rp,函数 f 的准确性可以通过均方误差(Mean Square Error, MSE)来度量。MSE 定义为:
MSE(f)=E[(Y−f(X))2]
其中,期望 E 是关于 X 和 Y 的联合分布取的。MSE 衡量了预测值 f(X) 与真实值 Y 之间的平均平方差异,是评估预测模型性能的重要指标。
直观解释:MSE 越小,表示模型的预测越准确。它惩罚较大的误差更严重(由于平方项),因此对异常值敏感。
MSE 的最小化器
理论表明,MSE 的最小化器是条件期望函数:
f∗(X)=E[Y∣X]
这意味着,当 f(X) 等于给定 X 时 Y 的条件期望时,MSE 达到最小值。这个结果来自概率论中的条件期望性质:E[Y∣X] 是 Y 在给定 X 下的最佳预测(在最小平方误差意义上)。
推导简要说明:
通过展开 MSE:
E[(Y−f(X))2]=E[(Y−E[Y∣X]+E[Y∣X]−f(X))2]
利用条件期望的性质,可以证明:
E[(Y−f(X))2]=E[(Y−E[Y∣X])2]+E[(E[Y∣X]−f(X))2]
由于第一项是常数(与 f 无关),最小化 MSE 等价于最小化第二项,即当 f(X)=E[Y∣X] 时,第二项为零。
训练误差
在实践中,联合分布 (X,Y) 是未知的,因此我们不能直接计算理论上的 MSE。 相反,我们基于样本数据集来近似均方误差(MSE) {(xi,yi)}i=1n.
MSE(f)=n1i=1∑n(yi−f(xi))2
这被称为经验风险或训练误差。然而,需要注意的是:
测试误差
使用独立测试样本(x0i,y0i)i=1m:
m1i=1∑m(y0i−f^(x0i))2
优势:更接近真实MSE,模拟未来待预测的观测值

偏差-方差分解
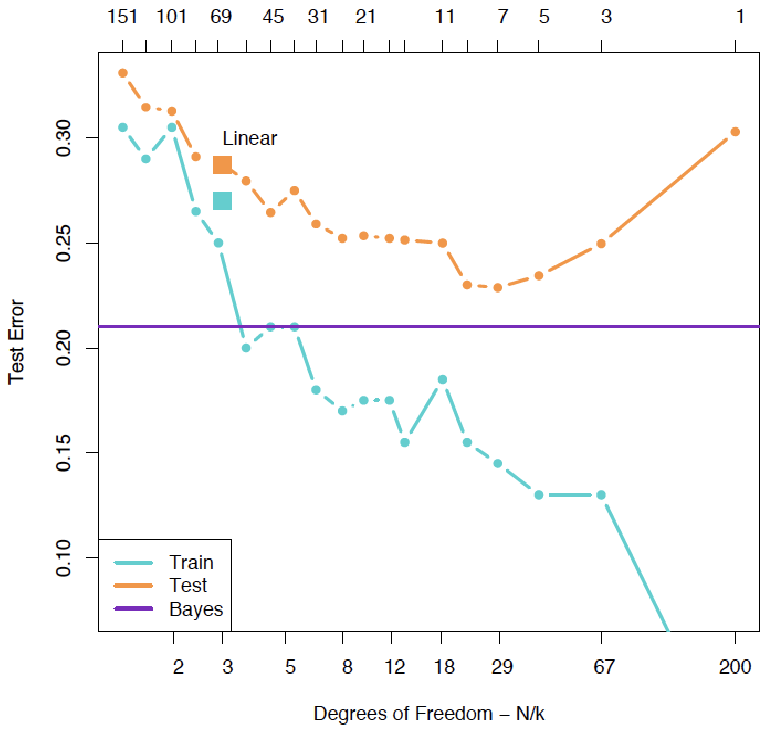
测试误差的U形曲线
测试误差随模型复杂度变化呈现典型的U形曲线,这是由两个相互竞争的量共同作用的结果:
E[(Y−f^(X))2]==E[(f^(X)−f(X))2]+var(ε)[Bias(f^(X))]2+var(f^(X))+var(ε)
关键说明:此分解揭示了预测误差的三个来源:偏差、方差和不可减少的误差。
偏差项
Bias(f^(X))=E[f^(X)]−f(X)
方差项
var(f^(X))=E[(f^(X)−E[f^(X)])2]
不可减少误差
var(ε)
偏差-方差权衡
随着模型复杂度增加:
-
偏差减小:复杂模型能更好地拟合数据中的复杂模式
-
方差增加:复杂模型对训练数据中的噪声更敏感
这种权衡关系导致了测试误差的U形曲线:
-
简单模型:高偏差,低方差(欠拟合)
-
复杂模型:低偏差,高方差(过拟合)
-
最优模型:在偏差和方差之间取得平衡
示例:在线性回归中,增加多项式特征可以降低偏差但会增加方差;正则化(如岭回归)可以减少方差但可能增加轻微偏差。
分类模型的评估
误分类误差 (Misclassification Error)
对于分类问题,其中 Y∈{1,…,K} 和 X∈Rp,函数 f 的准确性可以通过误分类误差来度量:
MCE(f)=E[I(Y=f(X))]
其中期望 E 是关于 X 和 Y 的联合分布取的,I(⋅) 是指示函数。
直观解释:误分类误差衡量的是模型做出错误分类的概率,是分类问题中最直接的性能度量指标。
贝叶斯规则 (Bayes Rule)
误分类误差的最小化器必须满足:
f∗(X)=kargmaxP(Y=k∣X)
这被称为贝叶斯规则或贝叶斯分类器,是在已知特征 X 的情况下最优的分类决策。
推导说明:对于任意分类规则 ϕ(X),其条件误分类误差为:
P(Y=ϕ(X)∣X=x)=1−P(Y=ϕ(x)∣X=x)
要最小化此概率,应选择 ϕ(x) 使得 P(Y=ϕ(x)∣X=x) 最大,即选择后验概率最大的类别。
训练误差与测试误差
训练误差
给定训练样本 {(xi,yi)}i=1n 和估计函数 f^,其训练误差为:
n1i=1∑nI(yi=f^(xi))
特点:衡量模型在训练数据上的表现,但可能低估真实的误分类误差。
测试误差
如果有测试样本 {(x0i,y0i)}i=1m,则 f^ 的测试误差为:
m1i=1∑mI(y0i=f^(x0i))
特点:提供模型在新数据上性能的无偏估计,是评估模型泛化能力的黄金标准。
交叉验证方法
验证集方法
优点:思想简单,易于实现
缺点:
-
验证MSE可能高度可变
-
仅使用部分观测值拟合模型,性能可能下降
留一法交叉验证(LOOCV)
步骤:
-
将大小为n的数据集分割为:训练集(n-1)和验证集(1)
-
使用训练集拟合模型
-
使用验证集验证模型,计算MSE
-
重复n次
-
计算平均MSE
优势:
-
偏差较小(使用n-1个观测值)
-
产生的MSE变异性较小
劣势:计算密集
K折交叉验证
步骤:
-
将训练样本分为A1,…,AK(通常K=5或10)
-
对每个k,使用除Ak外的所有数据拟合模型f^−k(x)
-
在Ak上计算预测误差:
Ek(f^)=i∈Ak∑L(yi,f^−k(xi))2
-
计算CV误差:
CV(f^)=n1k=1∑KEk(f^)
注:此处应有交叉验证过程示意图(附件页码)
交叉验证方法比较
基于三个模拟示例的对比:
-
蓝色:测试误差
-
黑色:LOOCV
-
橙色:10折CV
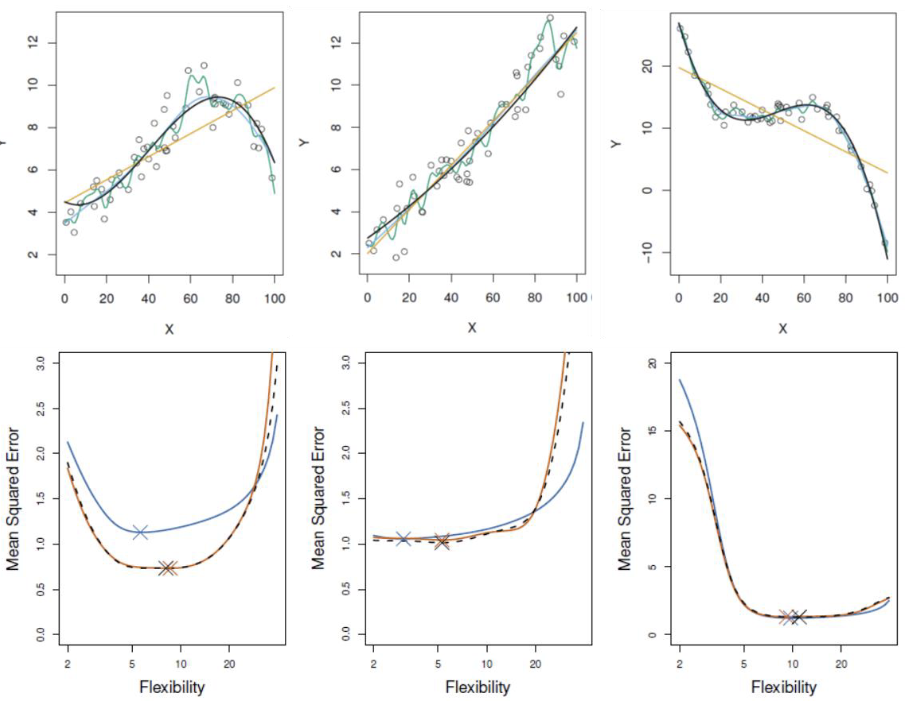
结论:
