#sdsc5001
English / 中文
Simple Linear Regression
基本设定
给定数据 (x1,y1),…,(xn,yn),其中:
回归函数表示为:
y=f(x)+ε
线性回归模型假设:
f(x)=β0+β1x
这通常被视为对真实关系的近似。
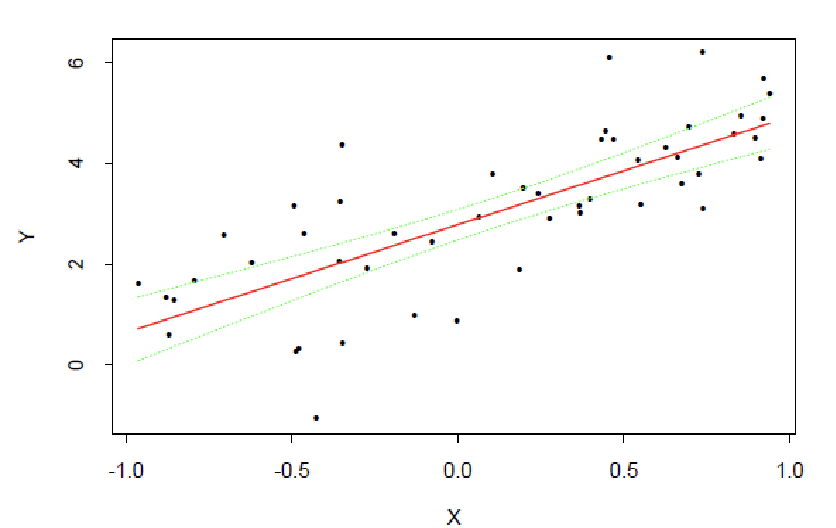
示例(附件页码2):一个简单的玩具示例展示数据点和线性拟合关系。

最小二乘拟合
通过最小化残差平方和来估计参数:
β0,β1mini=1∑n(yi−(β0+β1xi))2
解为:
β^1=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)(yi−yˉ)β^0=yˉ−β^1xˉ
其中:
参数估计与统计推断
模型假设
假设数据生成过程为:
Yi=β0+β1xi+εi
其中 εi 独立同分布于 N(0,σ2)
在此假设下,可以证明:
-
β^0 和 β^1 是 β0 和 β1 的无偏估计
β^1∼N(β1,∑i(xi−xˉ)2σ2)
-
β^1 是所有无偏线性估计量中方差最小的(BLUE估计量)
β^0∼N(β0,{n1+∑i(xi−xˉ)2xˉ2}σ2)
无偏性的推导
为了证明 β^1 是无偏的,我们首先写出 β^1 的公式:
β^1=∑i=1n(xi−xˉ)2∑i=1n(xi−xˉ)(yi−yˉ)
其中 xˉ=n1∑xi 和 yˉ=n1∑yi。
代入 yi=β0+β1xi+εi,并注意到 yˉ=β0+β1xˉ+εˉ,其中 εˉ=n1∑εi。
经过代数简化(具体步骤略),可得:
β^1=β1+∑(xi−xˉ)2∑(xi−xˉ)εi
取期望:
E[β^1]=E[β1+∑(xi−xˉ)2∑(xi−xˉ)εi]=β1+∑(xi−xˉ)2∑(xi−xˉ)E[εi]=β1
因为 E[εi]=0。因此,β^1 是无偏的。
类似地,对于 β^0=yˉ−β^1xˉ,取期望:
E[β^0]=E[yˉ]−xˉE[β^1]=(β0+β1xˉ)−xˉβ1=β0
所以 β^0 也是无偏的。
实际意义:无偏性意味着在多次重复抽样中,估计值的平均值会接近真实参数值,这增加了估计的可靠性。
BLUE性质的推导(高斯-马尔可夫定理)
高斯-马尔可夫定理指出,在线性回归模型中,如果误差项满足零均值、同方差且不相关,则最小二乘估计量 β^1 是所有线性无偏估计量中方差最小的。
考虑任何线性无偏估计量 b1=∑iciyi,其中 ci 是常数。无偏性要求 E[b1]=β1,这 implies ∑ci=0 和 ∑cixi=1(通过代入 yi 的表达式)。
方差为:
Var(b1)=Var(∑ciyi)=∑ci2Var(yi)=σ2∑ci2
因为 Var(yi)=σ2。
最小二乘估计量 β^1 的方差为:
Var(β^1)=∑(xi−xˉ)2σ2
通过优化问题,可以证明对于任何其他线性无偏估计量 b1,有 Var(b1)≥Var(β^1)。这体现了 β^1 的最小方差性。
实际意义:BLUE性质意味着OLS估计量是最精确的(方差最小),从而在统计推断中更有效,例如构建置信区间时更窄。
举例说明
假设我们有一个简单的数据集:房屋面积(xi)和房价(yi)。模型为 yi=β0+β1xi+εi。
-
β0 可能表示当面积为0时的基础房价(但实际中可能没有意义,所以常被视为模型偏移)。
-
β1 表示每增加一平方米,房价平均增加多少元。
-
无偏性:如果我们多次收集数据并计算 β^1,其平均值会接近真实的 β1。
-
BLUE:如果我们使用其他线性方法(如加权最小二乘),但权重选择不当,方差可能会更大,导致估计不如OLS稳定。
置信区间
σ2 可由无偏的MSE估计:
σ^2=MSE=n−2∑i=1n(yi−y^i)2
基于Cochran定理,β^0 和 β^1 的置信区间为:
β^j±t(2α,n−2)⋅se(β^j),j=0,1
符号定义与解释
-
σ2:误差项的方差,表示数据中无法由模型解释的变异程度。它是一个未知的常数参数。
-
σ^2 或 MSE:均方误差(Mean Squared Error),是 σ2 的无偏估计量。计算公式为 σ^2=MSE=n−2∑i=1n(yi−y^i)2,其中 n 是样本大小,n−2 是自由度(因为估计了两个参数 β0 和 β1)。MSE 衡量了模型预测的平均误差平方。
-
se(β^j):估计量 β^j 的标准误(standard error),表示 β^j 的抽样分布的标准差。对于简单线性回归,有:
- se(β^0)=MSE⋅(n1+∑i=1n(xi−xˉ)2xˉ2)
- se(β^1)=∑i=1n(xi−xˉ)2MSE
-
t(2α,n−2):t 分布的上 α/2 分位数,其中 α 是显著性水平(例如,95% 置信水平对应 α=0.05),n−2 是自由度。t 分布用于当总体方差未知时,代替正态分布构建置信区间。
置信区间的推导原理
置信区间的推导基于以下步骤:
-
抽样分布:在模型假设下(误差项 εi∼N(0,σ2) 且独立),最小二乘估计量 β^j 服从正态分布:
β^j∼N(βj,Var(β^j))
其中 Var(β^j) 是方差,取决于 σ2。
-
方差估计:由于 σ2 未知,我们使用 MSE 来估计它。Cochran 定理(或相关定理)确保:
- σ^2=MSE 与 β^j 独立。
- σ2(n−2)MSE∼χ2(n−2),即服从自由度为 n−2 的卡方分布。
-
t 统计量:将 β^j 标准化后,得到 t 统计量:
t=se(β^j)β^j−βj∼t(n−2)
这是因为:
t=Var(β^j)β^j−βj/σ2MSE=χn−22/(n−2)N(0,1)
这正好是 t 分布的定义。
-
置信区间:根据 t 分布的性质,有:
P(−tα/2,n−2≤se(β^j)β^j−βj≤tα/2,n−2)=1−α
重新排列不等式,得到置信区间:
β^j±tα/2,n−2⋅se(β^j)
这表示有 1−α 的置信度认为真实参数 βj 落在这个区间内。
实际意义与解释
置信区间提供了参数估计的不确定性度量。例如,对于 β1 的 95% 置信区间:
-
解释:如果我们重复抽样多次,每次计算一个置信区间,那么大约 95% 的这些区间会包含真实的 β1。
-
应用:如果置信区间包含零,可能表示该预测变量对响应变量没有显著影响(但需假设检验确认)。区间宽度反映了估计的精度:区间越窄,估计越精确。
-
例子:在房价预测模型中,如果 β1 表示面积对房价的影响,其 95% 置信区间为 [100, 200],则我们可以说“有 95% 的置信度认为,每增加一平方米,房价平均增加 100 到 200 元”。
举例说明
假设我们有一个简单线性回归模型,预测考试成绩(y)基于学习时间(x)。样本大小 n=20,计算得:
-
β^1=5(学习时间每增加一小时,成绩平均提高 5 分)
-
se(β^1)=0.8
-
MSE=10,自由度 n−2=18
-
对于 95% 置信区间,α=0.05,查 t 分布表得 t0.025,18≈2.101
则 β1 的置信区间为:
5±2.101×0.8=[3.32,6.68]
这意味着我们有 95% 的置信度认为,真实的学习时间效应介于 3.32 到 6.68 分之间。
假设检验
检验 H0:β1=0 vs H1:β1=0:
t1∗=se(β^1)β^1∼tn−2
如果 ∣t1∗∣>t(2α,n−2),拒绝 H0
示例:拟合线和置信带
多元线性回归
模型设定
yi=β0+β1xi1+⋯+βpxip+εi
矩阵形式:
y=Xβ+ε
其中:
-
y 是 n×1 响应向量
-
X 是 n×(p+1) 设计矩阵(第一列为1)
-
β 是 (p+1)×1 参数向量
最小二乘估计
目标函数
最小二乘法的目标是最小化残差平方和:
β^=βargmini=1∑n(yi−β0−j=1∑pβjxji)2=βargmin(y−Xβ)⊤(y−Xβ)
公式意义:左边是残差平方和的求和形式,右边是矩阵形式。y 是响应向量,X 是设计矩阵,β 是待估参数向量。
最小二乘解
通过求解上述优化问题,得到参数估计量:
β^=(X⊤X)−1X⊤y
统计性质:
- 期望:E[β^]=β(无偏估计)
- 协方差矩阵:cov(β^)=σ2(X⊤X)−1
拟合值与帽子矩阵
拟合值计算
利用参数估计量得到拟合值:
y^=Xβ^=X(X⊤X)−1X⊤y=Hy
其中 H=X(X⊤X)−1X⊤ 称为帽子矩阵。
帽子矩阵性质:
- H 是对称幂等矩阵(H2=H)
- 迹 tr(H)=p+1(参数个数)
- 将响应向量 y 投影到设计矩阵的列空间
拟合值的统计性质
E[y^]=Xβcov(y^)=σ2H
几何解释:拟合值 y^ 是 y 在设计矩阵列空间上的正交投影。
残差性质分析
残差定义与表达式
残差向量定义为观测值与拟合值之差:
e=y−y^=(I−H)y
残差的统计特性
E[e]=0cov(e)=σ2(I−H)
关键理解:
- 残差的期望为零,说明模型无系统偏差
- 残差的协方差矩阵不是对角阵,说明不同观测的残差之间存在相关性
- I−H 也是对称幂等矩阵,迹为 n−p−1
残差平方和的期望
残差平方和的期望值推导:
E[e⊤e]=E[tr(e⊤e)]=E[tr(ee⊤)]=tr(E[ee⊤])=tr(σ2(I−H))=σ2(n−p−1)
推导说明:
- 利用迹的循环置换性质:tr(ABC)=tr(BCA)
- E[ee⊤]=cov(e)=σ2(I−H)
- tr(H)=p+1,因此 tr(I−H)=n−(p+1)
方差估计
均方误差(MSE)
利用残差平方和估计误差方差:
σ^2=MSE=n−p−1e⊤e
统计意义:
- 分母 n−p−1 是残差的自由度
- 根据上述推导,E[σ^2]=σ2,是无偏估计
- 用于衡量模型的拟合优度和进行统计推断
模型评估
ANOVA分解
总平方和分解
在回归分析中,总变异可以分解为回归解释的变异和残差变异:
SSTO=SSE+SSR
其中:
-
SSTO:总平方和(Total Sum of Squares)
-
SSE:误差平方和(Error Sum of Squares)
-
SSR:回归平方和(Regression Sum of Squares)
矩阵形式表达
总平方和:
SSTO=yT(I−nJ)y
误差平方和:
SSE=eTe=yT(I−H)y=yTy−β^TXTy
回归平方和:
SSR=yT(H−nJ)y=β^TXTy−n(∑yi)2
符号说明:
- J 是全1矩阵(n×n,所有元素为1)
- H 是帽子矩阵 X(XTX)−1XT
- I 是单位矩阵
期望值推导
误差平方和的期望
E[SSE]=σ2(n−p−1)
推导说明:由于 E[eTe]=σ2(n−p−1),且 SSE=eTe
总平方和的期望
E[SSTO]=(n−1)σ2+βTXT(I−nJ)Xβ
统计意义:
回归平方和的期望
E[SSR]=pσ2+βTXT(I−nJ)Xβ
统计意义:
决定系数
R2=SSTOSSR=1−SSTOSSE
衡量模型解释的变异比例,取值范围为[0,1]。
调整决定系数
Radj2=1−SSTO/(n−1)SSE/(n−p−1)
考虑参数个数后的调整指标,用于比较不同复杂度的模型。
实际应用:ANOVA分析不仅提供模型整体显著性的检验,还为模型比较和选择提供重要依据。通过分解不同来源的变异,可以更好地理解模型的解释能力和拟合效果。
决定系数(R2)与调整决定系数
决定系数 R2
决定系数(系数 of multiple determination)定义为:
R2=SSTOSSR=1−SSTOSSE
统计意义:
-
衡量因变量Y的总变异中被预测变量X解释的比例
-
取值范围为[0,1],值越大表示模型拟合越好
-
反映模型对数据的解释能力
示例:如果R2=0.85,表示85%的Y变异可以被X解释,只有15%是随机误差。
R2的局限性
R2不适合用于比较不同模型,因为:
-
总是随着模型中变量数量的增加而增加
-
即使添加不相关的变量,R2也不会减小
-
可能导致过拟合问题
调整决定系数 Ra2
为了解决R2的局限性,引入调整决定系数:
Ra2=1−SSTO/(n−1)SSE/(n−p−1)=1−n−p−1n−1⋅SSTOSSE
优势:
比较规则:在模型比较中,应优先选择Ra2较大的模型。
线性模型的F检验
假设检验设置
检验整个回归模型的显著性:
H0:β1=β2=⋯=βp=0
Ha:至少有一个βk=0(k≥1)
原假设含义:所有斜率系数同时为0,即预测变量对响应变量没有线性影响。
F检验统计量
F∗=MSEMSR=SSE/(n−p−1)SSR/p
统计分布:在原假设成立条件下,F∗∼F(p,n−p−1)
决策规则:如果F∗>F(α;p,n−p−1),则拒绝原假设。
实际应用:F检验用于判断回归模型是否整体显著。如果拒绝H₀,说明至少有一个预测变量对响应变量有显著的线性影响。
回归系数的统计推断
系数估计的协方差矩阵
理论协方差矩阵:
cov(β^)=σ2(XTX)−1
估计的协方差矩阵(用MSE代替未知的σ²):
s2(β^)=MSE⋅(XTX)−1
单个系数的t检验
假设检验:
H0:βk=0,Ha:βk=0
检验统计量:
t∗=s(β^k)β^k−βk∼t(n−p−1);k=0,…,p
其中s(β^k)是s(β^)矩阵中相应的对角线元素(系数标准误)。
统计分布:在正态误差假设下,t∗∼t(n−p−1)
决策规则:如果∣t∗∣>t(α/2,n−p−1),则拒绝H₀。
置信区间构造
βk的100(1−α)%置信区间:
β^k±t(2α,n−p−1)⋅s(β^k)
实际应用示例
模型整体显著性检验
假设我们有p=3个预测变量,n=30个观测值:
-
计算得到F∗=15.2
-
查F分布表:F(0.05;3,26)≈2.98
-
由于15.2>2.98,拒绝H₀,模型整体显著
单个变量显著性检验
检验第二个预测变量的显著性:
-
β^2=2.5, s(β^2)=0.8
-
t∗=2.5/0.8=3.125
-
t(0.025,26)≈2.056
-
由于3.125>2.056,β2显著不为0
置信区间计算
β2的95%置信区间:
模型诊断
正态误差假设模型回顾
线性回归模型的基本形式:
yi=β0+j=1∑pβjxij+εi,i=1,…,n
模型假设:
-
β0,…,βp 是待估参数
-
xi 被视为固定常数(非随机变量)
-
εi 独立同分布于 N(0,σ2)
潜在问题与模型不适用性
线性回归模型可能不适用的情况包括:
-
回归函数非线性:真实关系不是线性形式
-
遗漏重要预测变量:模型缺少关键解释变量
-
误差方差异常:ε 的方差非常数(异方差性)
-
误差项不独立:ε 之间存在自相关
-
误差非正态分布:ε 不服从正态分布
-
异常值存在:少数极端观测值影响模型
-
预测变量相关:多重共线性问题
残差性质与诊断基础
残差的定义与性质
残差是误差项的估计:ei=yi−y^i
统计性质:
-
e∼N(0,σ2(I−H))
-
即使εi独立,ei也不独立(但大样本下近似独立)
-
E[ei]=0, Var(ei)=σ2(1−hii)
标准化残差
为更好地诊断模型,常使用标准化残差:
半学生化残差:
ei∗=MSEei
学生化残差(更常用):
ri=MSE(1−hii)ei
注:学生化残差考虑了每个观测点的杠杆效应,更适合异常值检测。
回归函数非线性检测
诊断方法
-
绘制残差与拟合值散点图
- 如果关系为线性,残差应随机分布在0附近
- 如果存在非线性模式,残差会显示系统性趋势

-
绘制残差与预测变量散点图
- 检查每个预测变量与残差的关系
- 系统性模式表明该变量的函数形式不正确
线性回归模型诊断与问题处理
遗漏重要预测变量的诊断与处理
诊断方法
通过绘制残差与其他预测变量的散点图来检测:
变量选择问题
当存在多个预测变量时,变量选择成为一个重要研究领域:
-
前向选择:从空模型开始,逐步添加显著变量
-
后向消除:从全模型开始,逐步移除不显著变量
-
逐步回归:结合前向和后向方法
-
正则化方法:LASSO、岭回归等
实践建议:变量选择应基于理论指导和统计准则(如AIC、BIC)相结合
异方差性(误差方差异常)检测
诊断方法
检查残差与拟合值的散点图(附件页码25):
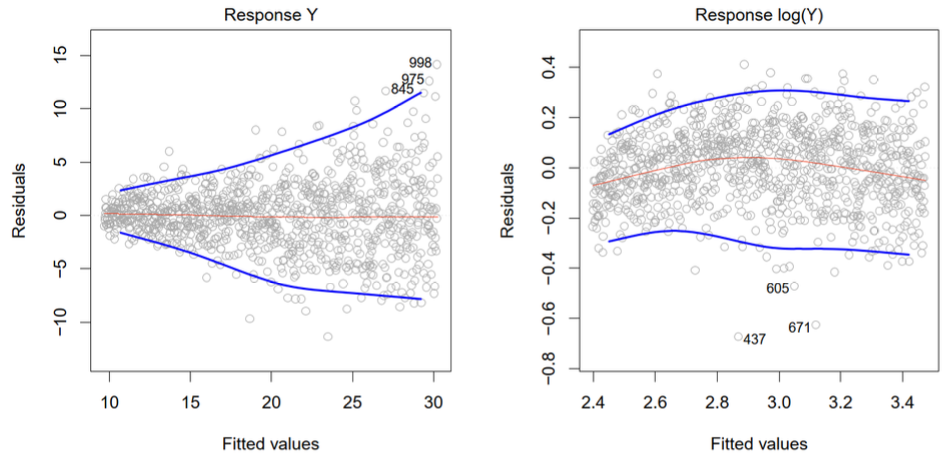
异方差性的影响
-
参数估计仍无偏,但标准误估计有偏
-
t检验和F检验失效
-
置信区间和预测区间不准确
模型诊断:误差项检验
误差项的依赖性(Dependence of Error Terms)
在时间序列或空间数据中,需要检查残差 ei 与时间或地理位置的散点图:

误差项的非正态性(Non-normality of Error Term)
检验残差 ei 正态性的三种方法:
-
分布图(Distribution Plots)
- 直方图:观察分布形状是否接近钟形曲线
- 箱线图:检测对称性和异常值
- 茎叶图:详细展示数据分布特征
-
累积分布函数比较
- 样本频率估计累积分布函数
- 与理论正态分布的累积分布函数进行比较
- 偏差较大表明非正态性
-
Q-Q 图(分位数-分位数图)
- 原理:比较样本分位数与理论正态分布分位数
- 判断标准:
- 点近似落在直线上 → 支持正态性假设
- 点明显偏离直线 → 误差项非正态分布
- 优势:对正态性偏离敏感,可视化效果好
模型诊断的核心是验证线性回归的基本假设是否成立,特别是误差项 ϵi 的独立同分布和正态性假设。这些诊断工具帮助识别模型缺陷,为模型改进提供方向。
异常观测值(Outlying Observations)
定义
-
异常点:与大多数数据明显分离的观测值
-
分类:
- 异常Y观测值(离群点):yi 远离模型预测值
- 异常X观测值(高杠杆点):具有异常X值的观测点

异常Y观测值的检测方法
残差类型及其定义
-
普通残差与半学生化残差
-
学生化残差
-
删除残差(Deleted Residual)
-
学生化删除残差
-
定义:ti=s(di)di=MSE(−i)(1−hii)ei
-
分布:ti∼tn−p−2
-
计算公式:ti=ei[SSE(1−hii)−ei2n−p−2]1/2
正式检验方法
-
检验统计量:比较 ∣ti∣ 与 t(1−2nα,n−p−2)
-
Bonferroni校正:调整显著性水平以考虑多重检验
异常X观测值的检测
杠杆值(Leverage)
-
定义:帽子矩阵 H=X(XTX)−1XT 的对角元素 hii
-
性质:
- 0≤hii≤1
- ∑i=1nhii=tr(H)=p+1
-
意义:衡量 xi 与所有X值中心的距离
-
判断标准:hii>n2(p+1) 表明异常X观测值
异常观测值检测是模型诊断的重要环节。离群点(Y异常)可能由测量误差引起,而高杠杆点(X异常)可能对回归结果产生过度影响。通过不同的残差定义和杠杆值分析,可以系统性地识别和处理这些异常点,提高模型的稳健性。
多重共线性(Multicollinearity)
定义与例子
-
多重共线性:预测变量之间存在高度相关性
-
理想情况:预测变量相互独立(统计中的"自变量")
-
例子:
- Y∼X1(weight)+X2(BMI)+others
- Y∼X1(credit rating)+X2(credit limit)+others
多重共线性的影响
方差膨胀因子(VIF)
变量变换
目的
-
线性化非线性回归函数
-
稳定误差方差
-
使误差项正态化
Box-Cox变换
-
变换形式:使用 yλ(λ≥0)作为响应变量,其中 y0 定义为 ln(Y)
-
选择最优λ:基于最大化似然函数
L(λ;β0,β1,σ2)=(2πσ)n/21exp(−2σ21i=1∑n(yi(λ)−β0−β1Txi)2)
偏差-方差权衡(Bias-Variance Tradeoff)
均方误差(MSE)分解
-
令 f0(x) 为 x 处的真实回归函数,则估计量 f^(x) 的均方误差为:
MSE(f^(x))=E[(f^(x)−f0(x))2]
-
分解为:
MSE(f^(x))=var(f^(x))+[E(f^(x))−f0(x)]2
- 第一项:方差(估计量的波动性)
- 第二项:偏差的平方(估计量的系统误差)
权衡关系与正则化
-
高斯-马尔可夫定理:如果线性模型正确,最小二乘估计 f^ 是无偏的,且在 y 的所有线性无偏估计量中方差最小
-
有偏估计的优势:可能存在MSE更小的有偏估计量
-
正则化方法:通过正则化减小方差,如果偏差增加很小则值得
- 子集选择(前向、后向、全子集)
- 岭回归(Ridge Regression)
- Lasso回归
-
现实情况:模型几乎从不完全正确,"最佳"线性模型与真实回归函数之间存在模型偏差
多重共线性会严重影响回归系数的解释和稳定性,需要通过VIF等指标检测。变量变换是改善模型假设的有效手段。偏差-方差权衡是模型选择的核心问题,正则化方法通过引入偏差来减小方差,可能获得更小的预测误差。
定性预测变量(Qualitative Predictors)
基本模型设定
考虑一个定量预测变量 X1 和一个有两个水平 M1 和 M2 的定性预测变量:
虚拟变量编码
-
定义:X2={10if level M1if level M2
-
回归模型:E(Y∣X)=β0+β1X1+β2X2
模型解释
-
对于水平 M1:E(Y∣X)=β0+β1X1+β2
-
对于水平 M2:E(Y∣X)=β0+β1X1
-
几何意义:不同截距但相同斜率的平行线
-
参数意义:β2=E(Y∣X2=1)−E(Y∣X2=0)=E(Y∣M1)−E(Y∣M2)
- β2 表示两个水平之间平均响应的差异
交互效应(Interaction Effects)
含交互项的模型
交互效应的意义
扩展说明
多定性预测变量
-
可以包含多个定性预测变量
-
每个定性变量需要单独编码
多水平定性变量
对于有5个水平的定性变量,编码方法:
方法1:序数编码(不推荐)
-
直接编码为1, 2, 3, 4, 5
-
问题:隐含序数关系,可能不符合实际
方法2:虚拟变量编码(推荐)
-
定义4个虚拟变量 X1,X2,X3,X4
-
Xj=1 如果水平 j,否则为0(j=1,2,3,4)
-
基准水平:第5个水平作为参考基准
方法3:效应编码
-
定义 X1,X2,X3,X4
-
Xj=1 如果水平 j,Xj=−1 如果水平5,否则为0
-
特点:参数表示与总体均值的偏差
定性预测变量通过虚拟变量编码引入回归模型,交互效应允许不同组别具有不同的斜率。多水平定性变量需要谨慎编码以避免虚假的序数关系,虚拟变量编码是最常用的方法。正确的编码方式对于模型解释和统计推断至关重要。
