
SDSC5001 Course 3-Overview of Statistical Machine Learning
#sdsc5001
English / 中文
Comparison of Terminology Between Statistics and Machine Learning
| Statistics | Machine Learning |
|---|---|
| Classification/Regression Clustering Classification/Regression with missing responses (Nonlinear) Dimensionality Reduction |
Supervised Learning Unsupervised Learning Semi-supervised Learning Manifold Learning |
| Covariates/Response Variables Sample/Population Statistical Model Misclassification/Prediction Error |
Features/Outcome Training Set/Test Set Learner Generalization Error |
| Multinomial Logistic Function Truncated Linear Function |
Softmax Function ReLU (Rectified Linear Unit) |
Key Note: The two fields use different terminology to describe similar concepts, but the core ideas are interconnected. For example, “covariates” in statistics correspond to “features” in machine learning.
Practical Application Cases
Wage Prediction Case
Task: Understand the relationship between employee wages and multiple factors

Data Source: Dataset collected based on male employees in the Atlantic region of the United States
Spam Detection Case
Task: Build a filter that can automatically detect spam emails
Data Representation:
| Observation | make% | address% | … | Total Capital Letters | Is Spam |
|---|---|---|---|---|---|
| 1 | 0 | 0.64 | … | 278 | 1(Yes) |
| 2 | 0.21 | 0.28 | … | 1028 | 1(Yes) |
| 3 | 0 | 0 | … | 7 | 0(No) |
| … | … | … | … | … | … |
| 4600 | 0.3 | 0 | … | 78 | 0(No) |
| 4601 | 0 | 0 | … | 40 | 0(No) |
Dataset Characteristics:
-
4601 emails, 2 categories
-
57 term frequency features
-
Simple classification function: , where is the indicator function
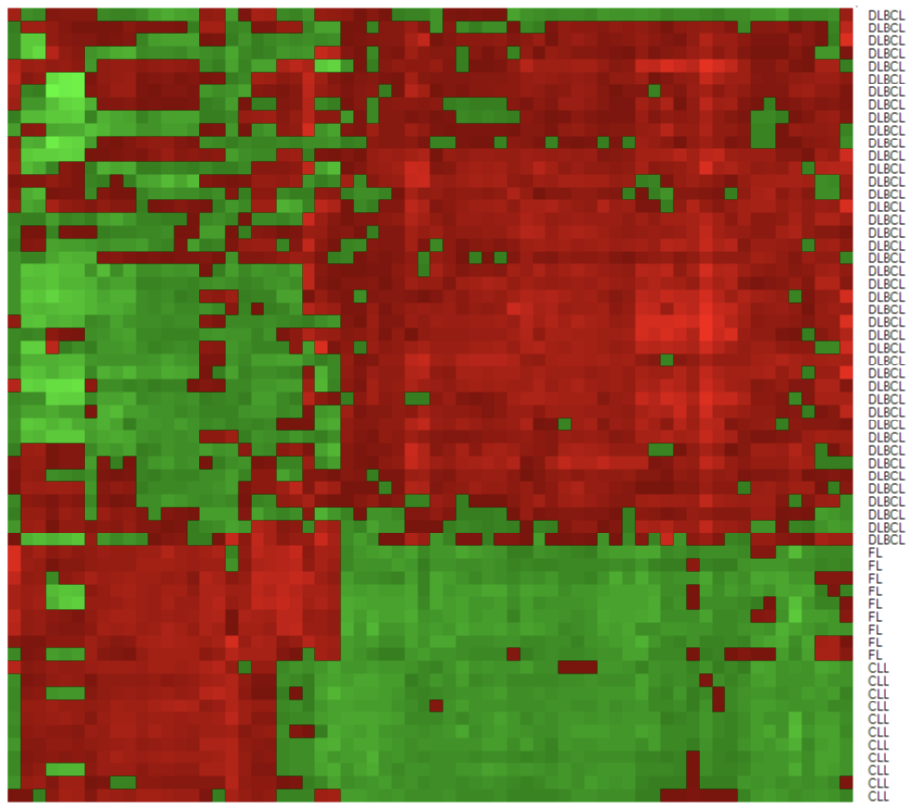
Gene Microarray Case
Task: Automatically diagnose cancer based on patient genotypes
Data Characteristics:
-
4026 gene expression profiles
-
62 patients, 3 types of adult lymphoid malignancies
-
66 “carefully” selected genes
Basic Notation
Training samples:
-
: input, feature vector, predictor variable, independent variable,
-
: output, response variable, dependent variable, scalar (can also be a real vector)
Data generation model:
-
: unknown function, represents systematic information about Y provided by X
-
: random error term, satisfying:
- Mean zero:
- Independent of X
Reasons for the error term :
-
Unmeasured factors
-
Measurement error
-
Intrinsic randomness
Estimation Methods
Parametric Models
-
Linear/Polynomial regression models
-
Generalized linear regression models
-
Fisher discriminant analysis
-
Logistic regression
-
Deep learning
Nonparametric Models
-
Local smoothing
-
Smoothing splines
-
Classification and regression trees, random forests, boosting methods
-
Support vector machines
Prediction and Inference
Prediction
Based on the estimated function , predict the response for new X:
Prediction error decomposition:
-
Reducible Error: Can be reduced by improving learning techniques
-
Irreducible Error: Cannot be eliminated due to being unpredictable by X
Inference
Goal: Understand how Y is affected by X
-
Which predictors are associated with Y?
-
How is Y related to each predictor?
-
How does Y change when intervening on certain predictors?
Balance between Prediction and Inference:
-
Simple models (e.g., linear models): High interpretability but possibly lower prediction accuracy
-
Complex nonlinear models: High prediction accuracy but poor interpretability
Classification Problems
Classification differs slightly from regression:
Classification decision function:
Misclassification error:
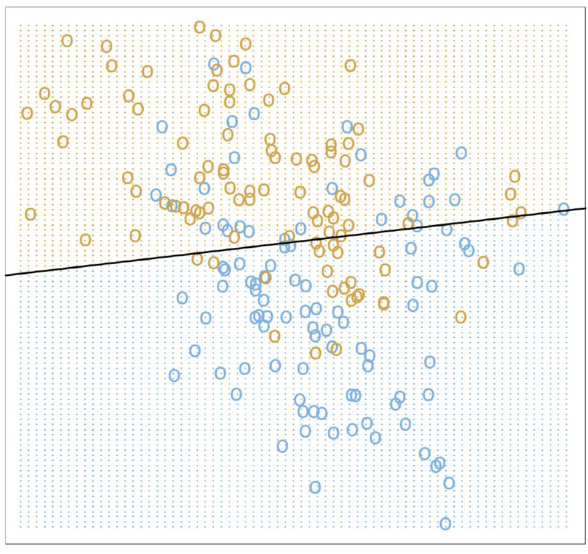
Example: Binary Classification Toy Problem
Problem Description: Simulate 200 points from an unknown distribution, two classes {blue, orange} with 100 each, build a prediction rule
Model 1: Linear Regression
Encoding: (orange), (blue)
Model form:
Parameter estimation (least squares):
Classification decision function:
Model 2: K-Nearest Neighbors (K-NN)
Prediction based on neighbors:
where is the neighborhood of X containing exactly k neighbors
Classification decision function (majority vote):
Model Complexity Comparison:
-
Linear regression: Uses 3 parameters
-
K-NN classifier: Uses effective parameters
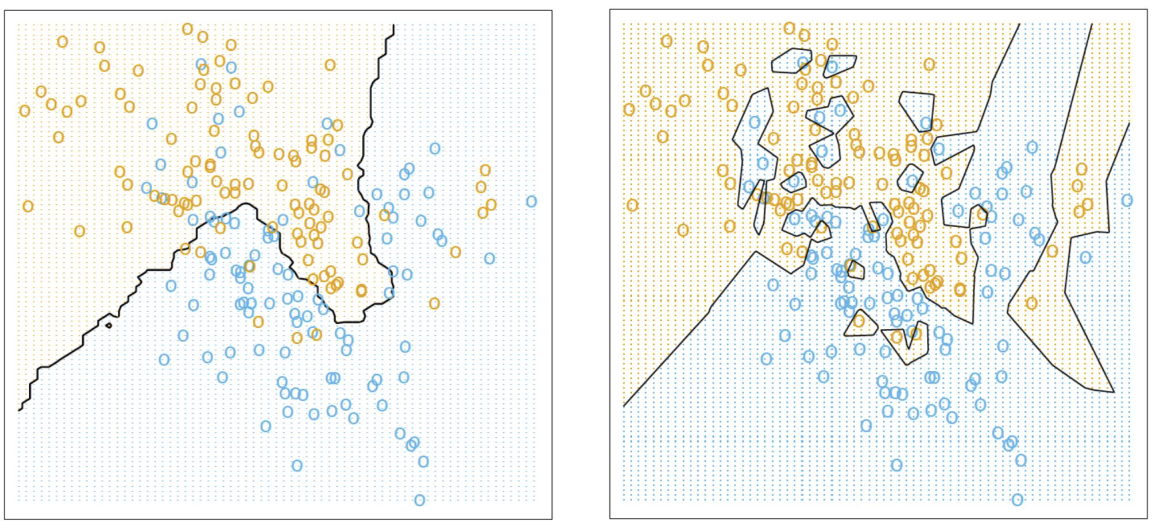
Comparison of 15-NN and 1-NN classification results
Regression Model Evaluation
Mean Squared Error (MSE) and Its Minimization
Definition of Mean Squared Error (MSE)
For regression problems where and , the accuracy of a function can be measured by the Mean Squared Error (MSE). MSE is defined as:
where the expectation is taken over the joint distribution of and . MSE measures the average squared difference between the predicted value and the true value , and is an important metric for evaluating the performance of predictive models.
Intuitive Explanation: A smaller MSE indicates more accurate predictions by the model. It penalizes larger errors more severely (due to the squared term), making it sensitive to outliers.
Minimizer of MSE
Theory shows that the minimizer of MSE is the conditional expectation function:
This means that MSE reaches its minimum when equals the conditional expectation of given . This result comes from the properties of conditional expectation in probability theory: is the best predictor of given (in the sense of minimizing squared error).
Brief derivation:
By expanding MSE:
Using properties of conditional expectation, it can be shown that:
Since the first term is constant (independent of ), minimizing MSE is equivalent to minimizing the second term, which is zero when .
Training Error
In practice, the joint distribution is unknown, so we cannot directly compute the theoretical MSE. Instead, we approximate the Mean Squared Error (MSE) based on a sample dataset .
This is called the empirical risk or training error. However, note that:
-
This estimate is an approximation of the theoretical MSE but may be biased, especially if the model overfits the training data.
-
Tends to underestimate the true MSE; complex models may achieve very small training errors
Test Error
Using independent test samples :
Advantage: Closer to the true MSE, simulates future observations to be predicted

Bias-Variance Decomposition
U-Shaped Curve of Test Error
The test error changes with model complexity in a typical U-shaped curve, resulting from the interaction of two competing quantities:
Key Note: This decomposition reveals three sources of prediction error: bias, variance, and irreducible error.
Bias Term
-
Definition: The difference between the expectation of the estimate and the true function
-
Meaning: Systematic error introduced by approximating with
-
Characteristic: Reflects the model’s fitting capability
Variance Term
-
Definition: The degree of fluctuation of the estimate around its expectation
-
Meaning: How much would change if estimated using different training sets
-
Characteristic: Reflects the model’s sensitivity to changes in training data
Irreducible Error
-
Definition: Variance of the random error term
-
Meaning: Error due to intrinsic randomness in the data, cannot be reduced by improving the model
-
Characteristic: Sets a theoretical lower bound for prediction error
Bias-Variance Trade-off
As model complexity increases:
-
Bias decreases: Complex models can better fit complex patterns in the data
-
Variance increases: Complex models are more sensitive to noise in the training data
This trade-off leads to the U-shaped curve of test error:
-
Simple models: High bias, low variance (underfitting)
-
Complex models: Low bias, high variance (overfitting)
-
Optimal model: Balances bias and variance
Example: In linear regression, adding polynomial features can reduce bias but increase variance; regularization (e.g., ridge regression) can reduce variance but may slightly increase bias.
Classification Model Evaluation
Misclassification Error
For classification problems where and , the accuracy of a function can be measured by the misclassification error:
where the expectation is taken over the joint distribution of and , and is the indicator function.
Intuitive Explanation: Misclassification error measures the probability that the model makes an incorrect classification, and is the most direct performance metric for classification problems.
Bayes Rule
The minimizer of misclassification error must satisfy:
This is called the Bayes rule or Bayes classifier, and is the optimal classification decision given the features .
Derivation Note:
For any classification rule , its conditional misclassification error is:
To minimize this probability, choose such that is maximized, i.e., choose the class with the highest posterior probability.
Training Error and Test Error
Training Error
Given training samples and an estimated function , its training error is:
Characteristic: Measures the model’s performance on training data, but may underestimate the true misclassification error.
Test Error
If there are test samples , the test error of is:
Characteristic: Provides an unbiased estimate of the model’s performance on new data, and is the gold standard for evaluating model generalization ability.
Cross-Validation Methods
Validation Set Method
Advantages: Simple idea, easy to implement
Disadvantages:
-
Validation MSE can be highly variable
-
Uses only part of the observations to fit the model, performance may degrade
Leave-One-Out Cross-Validation (LOOCV)
Steps:
-
Split the dataset of size n into: training set (n-1) and validation set (1)
-
Fit the model using the training set
-
Validate the model using the validation set, compute MSE
-
Repeat n times
-
Compute the average MSE
Advantages:
-
Low bias (uses n-1 observations)
-
Produces less variable MSE
Disadvantages: Computationally intensive
K-Fold Cross-Validation
Steps:
-
Divide the training samples into (usually K=5 or 10)
-
For each k, fit the model using all data except
-
Compute the prediction error on :
-
Compute the CV error:
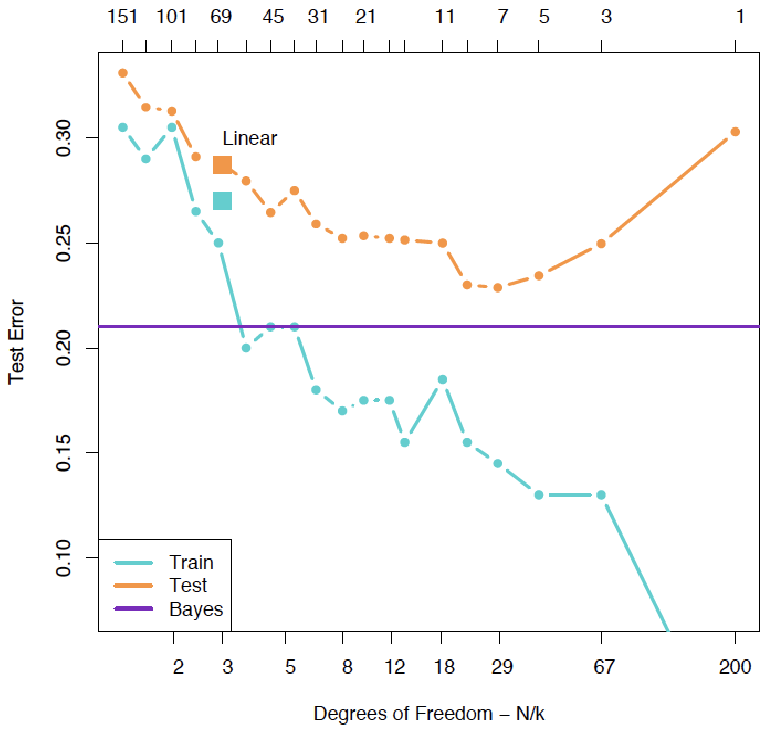
Comparison of Cross-Validation Methods
Based on comparison of three simulated examples:
-
Blue: Test error
-
Black: LOOCV
-
Orange: 10-fold CV
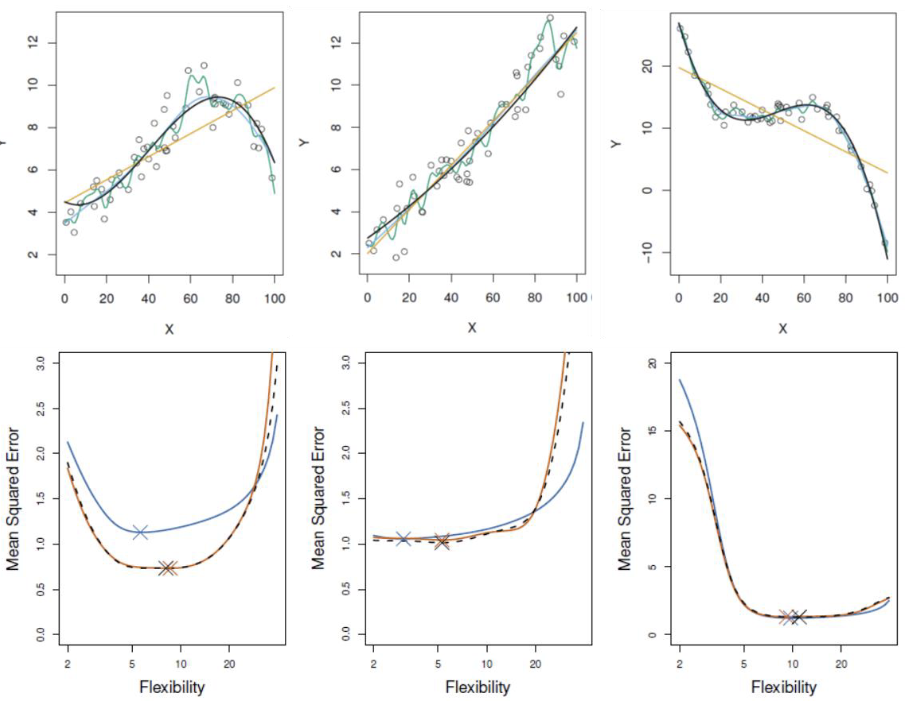
Conclusions:
-
LOOCV has lower bias than K-fold CV (when )
-
LOOCV has higher variance than K-fold CV (when )
-
In practice, K-fold CV with K=5 or 10 is commonly used
-
Empirical evidence shows that K-fold CV provides reasonable estimates of test error