
SDSC5001 Course 4-Linear Regression
#sdsc5001
English / 中文
Simple Linear Regression
Basic Setup
Given data , where:
-
is the predictor variable (independent variable, input, feature)
-
is the response variable (dependent variable, output, outcome)
The regression function is expressed as:
The linear regression model assumes:
This is usually considered an approximation of the true relationship.
Example (Attachment Page 2): A simple toy example showing data points and linear fit.

Least Squares Fitting
Parameters are estimated by minimizing the residual sum of squares:
The solutions are:
Where:
-
is the fitted value
-
is the residual
Parameter Estimation and Statistical Inference
Model Assumptions
Assume the data generating process is:
where are i.i.d.
Under these assumptions, it can be proven:
-
and are unbiased estimators of and
-
has the smallest variance among all unbiased linear estimators (BLUE estimator)
Derivation of Unbiasedness
To prove is unbiased, we first write the formula for :
where and .
Substitute , and note that , where .
After algebraic simplification (specific steps omitted), we get:
Taking expectation:
because . Therefore, is unbiased.
Similarly, for , taking expectation:
So is also unbiased.
Practical Significance: Unbiasedness means that over many repeated samples, the average of the estimates will be close to the true parameter value, increasing the reliability of the estimation.
Derivation of BLUE Property (Gauss-Markov Theorem)
The Gauss-Markov theorem states that in the linear regression model, if the error terms have zero mean, constant variance, and are uncorrelated, then the least squares estimator has the smallest variance among all linear unbiased estimators.
Consider any linear unbiased estimator , where are constants. Unbiasedness requires , which implies and (by substituting the expression for ).
The variance is:
because .
The variance of the least squares estimator is:
Through an optimization problem, it can be shown that for any other linear unbiased estimator , . This demonstrates the minimum variance property of .
Practical Significance: The BLUE property means the OLS estimator is the most precise (minimum variance), thus more efficient in statistical inference, e.g., producing narrower confidence intervals.
Illustrative Example
Suppose we have a simple dataset: house area () and house price (). The model is .
-
might represent the base price when the area is 0 (though this may not be meaningful in practice, so it is often considered a model offset).
-
represents the average increase in price per additional square meter.
-
Unbiasedness: If we collect data multiple times and compute , its average will be close to the true .
-
BLUE: If we use other linear methods (e.g., weighted least squares) but choose weights inappropriately, the variance might be larger, making the estimation less stable than OLS.
Confidence Intervals
can be estimated unbiasedly by MSE:
Based on Cochran’s theorem, the confidence intervals for and are:
Symbol Definitions and Interpretations
-
: Variance of the error term, representing the variation in the data not accounted for by the model. It is an unknown constant parameter.
-
or MSE: Mean Squared Error, an unbiased estimator of . Calculated as , where is the sample size, and is the degrees of freedom (because two parameters and are estimated). MSE measures the average squared prediction error of the model.
-
: Standard error of the estimator , representing the standard deviation of the sampling distribution of . For simple linear regression:
-
: The upper quantile of the t-distribution, where is the significance level (e.g., 95% confidence level corresponds to ), and is the degrees of freedom. The t-distribution is used instead of the normal distribution to construct confidence intervals when the population variance is unknown.
Derivation Principle of Confidence Intervals
The derivation of confidence intervals is based on the following steps:
-
Sampling Distribution: Under the model assumptions (error terms and independent), the least squares estimators follow a normal distribution:
where is the variance, depending on .
-
Variance Estimation: Since is unknown, we use MSE to estimate it. Cochran’s theorem (or related theorems) ensures:
- is independent of .
- , i.e., follows a chi-square distribution with degrees of freedom.
-
t-statistic: Standardizing gives the t-statistic:
This is because:
which is exactly the definition of the t-distribution.
-
Confidence Interval: Based on the properties of the t-distribution:
Rearranging the inequality gives the confidence interval:
This means we are confident that the true parameter lies within this interval.
Practical Significance and Interpretation
Confidence intervals provide a measure of uncertainty for parameter estimates. For example, for a 95% confidence interval for :
-
Interpretation: If we repeatedly sample many times and compute a confidence interval each time, about 95% of these intervals will contain the true .
-
Application: If the confidence interval includes zero, it may indicate that the predictor variable has no significant effect on the response variable (but needs hypothesis testing confirmation). The width of the interval reflects the precision of the estimate: a narrower interval indicates higher precision.
-
Example: In a house price prediction model, if represents the effect of area on price, and its 95% confidence interval is [100, 200], we can say “we are 95% confident that for each additional square meter, the house price increases by an average of 100 to 200 units.”
Illustrative Example
Suppose we have a simple linear regression model predicting test scores () based on study time (). Sample size , calculations give:
-
(each additional hour of study time increases the score by 5 points on average)
-
-
, degrees of freedom
-
For a 95% confidence interval, , from the t-distribution table
Then the confidence interval for is:
This means we are 95% confident that the true effect of study time is between 3.32 and 6.68 points.
Hypothesis Testing
Test vs :
If , reject
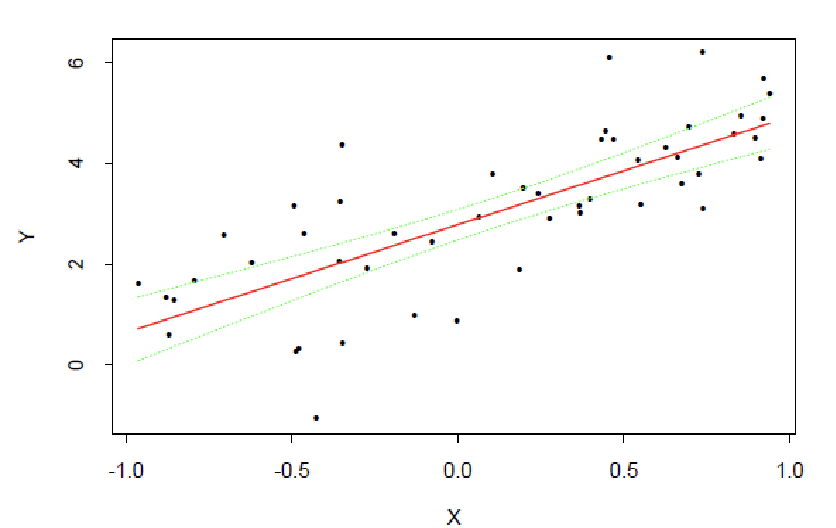
Example: Fitted line and confidence band
Multiple Linear Regression
Model Setup
Matrix form:
Where:
-
is the response vector
-
is the design matrix (first column is 1s)
-
is the parameter vector
Least Squares Estimation
Objective Function
The goal of least squares is to minimize the residual sum of squares:
Formula Meaning: The left side is the summation form of the residual sum of squares, the right side is the matrix form. is the response vector, is the design matrix, is the parameter vector to be estimated.
Least Squares Solution
Solving the above optimization problem gives the parameter estimator:
Statistical Properties:
- Expectation: (unbiased estimator)
- Covariance matrix:
Fitted Values and Hat Matrix
Fitted Value Calculation
Using the parameter estimator to get fitted values:
where is called the hat matrix.
Hat Matrix Properties:
- is a symmetric idempotent matrix ()
- Trace (number of parameters)
- Projects the response vector onto the column space of the design matrix
Statistical Properties of Fitted Values
Geometric Interpretation: The fitted values are the orthogonal projection of onto the column space of the design matrix.
Residual Properties Analysis
Residual Definition and Expression
The residual vector is defined as the difference between observed and fitted values:
Statistical Properties of Residuals
Key Understanding:
- The expectation of residuals is zero, indicating no systematic bias in the model
- The covariance matrix of residuals is not diagonal, indicating correlation between residuals of different observations
- is also a symmetric idempotent matrix, trace is
Expectation of Residual Sum of Squares
Derivation of the expected value of the residual sum of squares:
Derivation Explanation:
- Using the cyclic property of trace:
- , so
Variance Estimation
Mean Squared Error (MSE)
Using the residual sum of squares to estimate the error variance:
Statistical Meaning:
- Denominator is the degrees of freedom of the residuals
- From the above derivation, , it is an unbiased estimator
- Used to measure model goodness-of-fit and for statistical inference
Model Evaluation
ANOVA Decomposition
Total Sum of Squares Decomposition
In regression analysis, the total variation can be decomposed into variation explained by regression and residual variation:
Where:
-
: Total Sum of Squares
-
: Error Sum of Squares
-
: Regression Sum of Squares
Matrix Form Expressions
Total Sum of Squares:
Error Sum of Squares:
Regression Sum of Squares:
Symbol Explanation:
- is the matrix of ones (, all elements are 1)
- is the hat matrix
- is the identity matrix
Expectation Derivation
Expectation of Error Sum of Squares
Derivation Explanation:
Since , and
Expectation of Total Sum of Squares
Statistical Meaning:
-
: Variation due to random error
-
: Systematic variation explained by the model
Expectation of Regression Sum of Squares
Statistical Meaning:
-
: Variation due to parameter estimation uncertainty
-
: Variation explained by the true regression effect
Coefficient of Determination
Measures the proportion of variation explained by the model, range [0,1].
Adjusted Coefficient of Determination
Adjusted index considering the number of parameters, used for comparing models of different complexity.
Practical Application: ANOVA analysis not only provides tests for the overall significance of the model but also important basis for model comparison and selection. By decomposing variations from different sources, we can better understand the model’s explanatory power and fitting effect.
Coefficient of Determination () and Adjusted
Coefficient of Determination
The coefficient of multiple determination is defined as:
Statistical Meaning:
-
Measures the proportion of total variation in the dependent variable Y explained by the predictor variables X
-
Range [0,1], larger value indicates better model fit
-
Reflects the model’s explanatory power for the data
Example: If , it means 85% of the variation in Y can be explained by X, only 15% is random error.
Limitations of
is not suitable for comparing different models because:
-
It always increases as the number of variables in the model increases
-
Even if irrelevant variables are added, does not decrease
-
May lead to overfitting problems
Adjusted Coefficient of Determination
To address the limitations of , the adjusted coefficient of determination is introduced:
Advantages:
-
Penalizes for the number of variables, avoiding overfitting
-
More suitable for comparing models of different complexity
-
increases only if the new variable improves the model sufficiently
Comparison Rule: In model comparison, prefer models with larger .
F-Test for Linear Models
Hypothesis Test Setup
Test the overall significance of the regression model:
Null Hypothesis Meaning: All slope coefficients are simultaneously 0, meaning the predictor variables have no linear effect on the response variable.
F-Test Statistic
Statistical Distribution: Under the null hypothesis,
Decision Rule: If , reject the null hypothesis.
Practical Application: The F-test is used to determine if the regression model is overall significant. If H₀ is rejected, it indicates that at least one predictor variable has a significant linear effect on the response variable.
Statistical Inference for Regression Coefficients
Covariance Matrix of Coefficient Estimates
Theoretical covariance matrix:
Estimated covariance matrix (using MSE instead of unknown σ²):
t-Test for Individual Coefficients
Hypothesis Test:
Test Statistic:
Where is the corresponding diagonal element in the matrix (coefficient standard error).
Statistical Distribution: Under normal error assumption,
Decision Rule: If , reject H₀.
Confidence Interval Construction
confidence interval for :
Practical Application Example
Overall Model Significance Test
Suppose we have p=3 predictor variables, n=30 observations:
-
Calculated
-
From F-distribution table:
-
Since , reject H₀, the model is overall significant
Individual Variable Significance Test
Test the significance of the second predictor variable:
-
,
-
-
-
Since , is significantly different from 0
Confidence Interval Calculation
95% confidence interval for :
Model Diagnostics
Review of Normal Error Assumption Model
Basic form of linear regression model:
Model Assumptions:
-
are parameters to be estimated
-
are treated as fixed constants (non-random variables)
-
are i.i.d.
Potential Problems and Model Inapplicability
Situations where the linear regression model may not be applicable include:
-
Nonlinear regression function: The true relationship is not linear
-
Omission of important predictor variables: The model lacks key explanatory variables
-
Non-constant error variance: Variance of is not constant (heteroscedasticity)
-
Dependent error terms: Autocorrelation exists among
-
Non-normal error distribution: does not follow a normal distribution
-
Presence of outliers: A few extreme observations affect the model
-
Correlated predictor variables: Multicollinearity problem
Residual Properties and Diagnostic Basics
Definition and Properties of Residuals
Residuals are estimates of error terms:
Statistical Properties:
-
-
Even if are independent, are not independent (but approximately independent in large samples)
-
,
Standardized Residuals
For better model diagnostics, standardized residuals are often used:
Semi-studentized residuals:
Studentized residuals (more commonly used):
Note: Studentized residuals account for the leverage effect of each observation, more suitable for outlier detection.
Detection of Nonlinear Regression Function
Diagnostic Methods
-
Plot residuals vs. fitted values scatter plot
- If the relationship is linear, residuals should be randomly distributed around 0
- If nonlinear patterns exist, residuals will show systematic trends

-
Plot residuals vs. predictor variables scatter plots
- Check the relationship between each predictor variable and residuals
- Systematic patterns indicate incorrect functional form for that variable
Linear Regression Model Diagnostics and Problem Handling
Diagnostics and Handling of Omitted Important Predictor Variables
Diagnostic Methods
Detect by plotting residuals against other predictor variables:
-
If residuals show systematic patterns with a predictor variable not included, it suggests that variable should be included in the model
-
Any non-random patterns in residuals may indicate omission of important variables
Variable Selection Problem
When multiple predictor variables exist, variable selection becomes an important research area:
-
Forward selection: Start with an empty model, add significant variables step by step
-
Backward elimination: Start with the full model, remove insignificant variables step by step
-
Stepwise regression: Combines forward and backward methods
-
Regularization methods: LASSO, Ridge regression, etc.
Practical Advice: Variable selection should combine theoretical guidance and statistical criteria (e.g., AIC, BIC)
Heteroscedasticity (Non-constant Error Variance) Detection
Diagnostic Methods
Check scatter plot of residuals vs. fitted values (attachment page 25):
-
Ideally, all residuals should have roughly the same variability
-
Increasing (or decreasing) residual variability with fitted values indicates heteroscedasticity
-
Since the sign of residuals is less important for detecting heteroscedasticity, often use scatter plots of or vs.
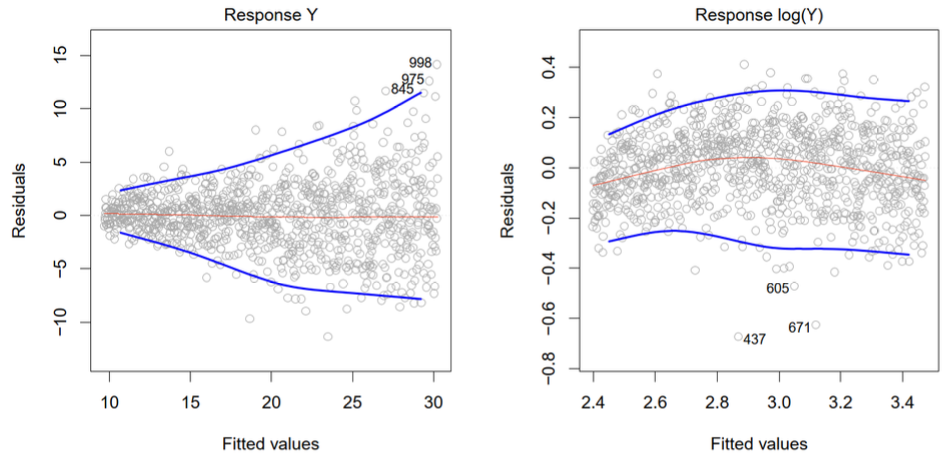
Effects of Heteroscedasticity
-
Parameter estimates remain unbiased, but standard error estimates are biased
-
t-tests and F-tests become invalid
-
Confidence intervals and prediction intervals are inaccurate
Model Diagnostics: Error Term Tests
Dependence of Error Terms
In time series or spatial data, check scatter plots of residuals against time or geographical location:
-
Purpose: Detect if there is correlation between adjacent residuals in the sequence
-
Method: Plot against time or spatial location
-
Ideal situation: Residuals should be randomly distributed, no specific pattern

Non-normality of Error Term
Three methods to test the normality of residuals :
-
Distribution Plots
- Histogram: Observe if the distribution shape is close to a bell curve
- Box plot: Detect symmetry and outliers
- Stem-and-leaf plot: Detailed display of data distribution characteristics
-
Cumulative Distribution Function Comparison
- Estimate the sample cumulative distribution function
- Compare with the theoretical normal cumulative distribution function
- Large deviations indicate non-normality
-
Q-Q Plot (Quantile-Quantile Plot)
- Principle: Compare sample quantiles with theoretical normal distribution quantiles
- Judgment Criterion:
- Points approximately on a straight line → Support normality assumption
- Points significantly deviate from the line → Error terms are non-normal
- Advantage: Sensitive to deviations from normality, good visualization effect
The core of model diagnostics is to verify whether the basic assumptions of linear regression hold, especially the i.i.d. and normality assumptions of the error terms . These diagnostic tools help identify model defects and provide direction for model improvement.
Outlying Observations
Definition
-
Outlier: An observation significantly separated from the majority of the data
-
Classification:
- Outlying Y observation (outlier): is far from the model predicted value
- Outlying X observation (high leverage point): Observation with unusual X values

Detection Methods for Outlying Y Observations
Types of Residuals and Their Definitions
-
Ordinary Residuals and Semi-studentized Residuals
-
Ordinary residual:
-
Semi-studentized residual:
-
Studentized Residuals
-
Definition:
-
Characteristic: Accounts for differences in residual variability
-
Deleted Residual
-
Definition:
- : Model predicted value fitted without the i-th observation
-
Property:
-
Meaning: Simulates prediction error for a new observation
-
Studentized Deleted Residual
-
Definition:
-
Distribution:
-
Calculation formula:
Formal Test Methods
-
Test statistic: Compare with
-
Bonferroni correction: Adjust significance level to account for multiple testing
Detection of Outlying X Observations
Leverage
-
Definition: Diagonal elements of the hat matrix
-
Properties:
-
Meaning: Measures the distance of from the center of all X values
-
Judgment criterion: indicates an outlying X observation
Outlier detection is an important part of model diagnostics. Outliers (Y anomalies) may be caused by measurement errors, while high leverage points (X anomalies) may have excessive influence on regression results. Through different residual definitions and leverage analysis, these outliers can be systematically identified and handled, improving model robustness.
Multicollinearity
Definition and Examples
-
Multicollinearity: High correlation exists among predictor variables
-
Ideal situation: Predictor variables are independent of each other (“independent variables” in statistics)
-
Examples:
Effects of Multicollinearity
-
Variance of regression coefficient estimates becomes very large
-
After deleting one variable, regression coefficients may change sign
-
Marginal significance of predictor variables highly depends on other predictor variables included in the model
-
Significance of predictor variables may be masked by correlated variables in the model
Variance Inflation Factor (VIF)
-
Definition:
- Where is the coefficient of determination obtained by regressing the j-th variable on the other variables in the model
-
Judgment criterion:
- Maximum VIF > 10 → Multicollinearity is considered to have an undue influence on least squares estimates
- Average of all VIFs much greater than 1 → Indicates serious multicollinearity
Variable Transformation
Purpose
-
Linearize nonlinear regression functions
-
Stabilize error variance
-
Normalize error terms
Box-Cox Transformation
-
Transformation form: Use () as the response variable, where is defined as
-
Choose optimal : Based on maximizing the likelihood function
Bias-Variance Tradeoff
Mean Squared Error (MSE) Decomposition
-
Let be the true regression function at , then the mean squared error of the estimator is:
-
Decomposed as:
- First term: Variance (fluctuation of the estimator)
- Second term: Squared bias (systematic error of the estimator)
Tradeoff Relationship and Regularization
-
Gauss-Markov theorem: If the linear model is correct, the least squares estimator is unbiased and has the smallest variance among all linear unbiased estimators of
-
Advantage of biased estimators: There may exist biased estimators with smaller MSE
-
Regularization methods: Reduce variance through regularization, worthwhile if the increase in bias is small
- Subset selection (forward, backward, all subsets)
- Ridge Regression
- Lasso regression
-
Reality: Models are almost never completely correct, there is model bias between the “best” linear model and the true regression function
Multicollinearity seriously affects the interpretation and stability of regression coefficients and needs to be detected by indicators like VIF. Variable transformation is an effective means to improve model assumptions. The bias-variance tradeoff is the core issue in model selection; regularization methods may achieve smaller prediction errors by introducing bias to reduce variance.
Qualitative Predictors
Basic Model Setup
Consider a quantitative predictor variable and a qualitative predictor with two levels and :
Dummy Variable Coding
-
Definition:
-
Regression model:
Model Interpretation
-
For level :
-
For level :
-
Geometric meaning: Parallel lines with different intercepts but same slope
-
Parameter meaning:
- represents the difference in average response between the two levels
Interaction Effects
Model with Interaction Term
-
Model form:
-
Model interpretation:
- For level :
- For level :
Meaning of Interaction Effects
-
Geometric meaning: Non-parallel lines with different intercepts and slopes
-
Parameter interpretation:
- : Difference in intercepts between the two levels at
- : Difference in slopes between the two levels
-
Interaction term: allows the slope to vary with the level of the qualitative variable
Extended Explanation
Multiple Qualitative Predictors
-
Can include multiple qualitative predictors
-
Each qualitative variable needs separate coding
Multi-level Qualitative Variables
For a qualitative variable with 5 levels, coding methods:
Method 1: Ordinal Coding (Not Recommended)
-
Directly code as 1, 2, 3, 4, 5
-
Problem: Implies ordinal relationship, may not reflect reality
Method 2: Dummy Variable Coding (Recommended)
-
Define 4 dummy variables
-
if level , otherwise 0 ()
-
Baseline level: The 5th level serves as the reference baseline
Method 3: Effect Coding
-
Define
-
if level , if level 5, otherwise 0
-
Characteristic: Parameters represent deviations from the overall mean
Qualitative predictors are introduced into the regression model through dummy variable coding. Interaction effects allow different groups to have different slopes. Multi-level qualitative variables require careful coding to avoid spurious ordinal relationships; dummy variable coding is the most commonly used method. Correct coding is essential for model interpretation and statistical inference.