SDSC6007 课程 1
#sdsc6007
English / 中文
简介
离散时间动态系统 (The Discrete-Time Dynamic System)
该系统具有以下形式:
xk+1=fk(xk,uk,wk),k=0,1,…,N−1,
其中:
-
k:离散时间索引
-
N:时间范围(Horizon)或控制被应用的次数
-
xk:系统的状态,属于状态集合 Sk
-
uk:在时间 k 需要选择的控制变量/决策变量/动作(control/decision variable/action),从集合 Uk(xk) 中选择
-
wk:一个随机参数(也称为扰动 disturbance)
-
fk:描述状态如何更新的函数
假设 (Assumption)
wk 是相互独立的。其概率分布可能依赖于 xk 和 uk。
本质上是对该系统在离散的时间/控制状态内通过有限/无限状态 xN 以描述整个系统,该状态在时序上受到 uk∈Uk(xk) 决策变量/动作与随机参数 wk 影响与控制。
代价函数 (The Cost Function)
(期望)代价具有以下形式:
E[gN(xN)+k=0∑N−1gk(xk,uk,wk)]
其中:
-
gk(xk,uk,wk):在时间 k 产生的代价
-
gN(xN):在过程结束时产生的终端代价 (terminal cost)
注意 (Note)
由于 wk 的存在,代价是一个随机变量,因此我们是在优化其期望值。
没啥好说的,就是损失函数的集合形式。
确定性调度问题
示例
教授计划生产性能优于现用BearPods 3的豪华耳机,需在特定机器上执行A、B、C、D四个操作,且满足:
-
操作B必须在操作A完成后执行
-
操作D必须在操作C完成后执行
定义:
解法
-
需做三次决策(最后一次由前三次决定)
-
确定性系统(无 wk)
-
有限状态数问题 ⇒ 状态转移图
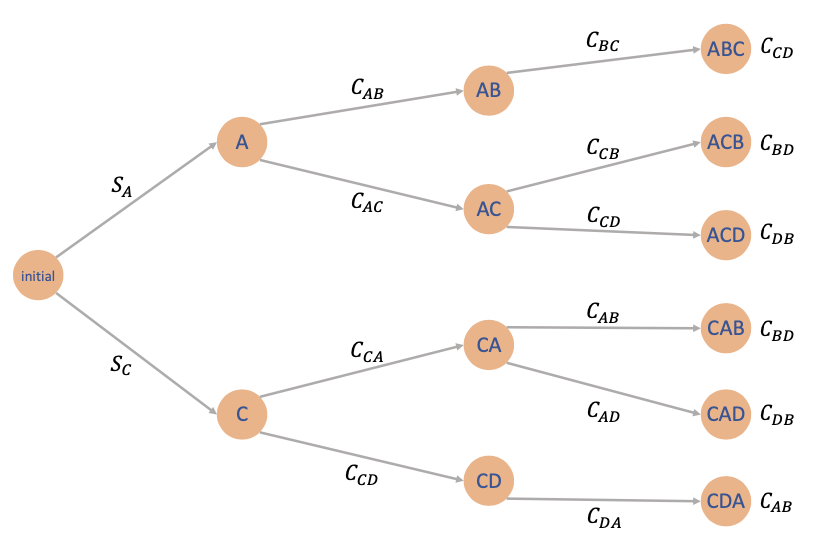
离散状态与有限状态问题
为描述状态间转移,常定义转移概率:
pij(u,k)=P(xk+1=j∣xk=i,uk=u)
在动态系统中,这等价于 xk+1=wk,其中 wk 服从由 pij(u,k) 定义的概率分布。
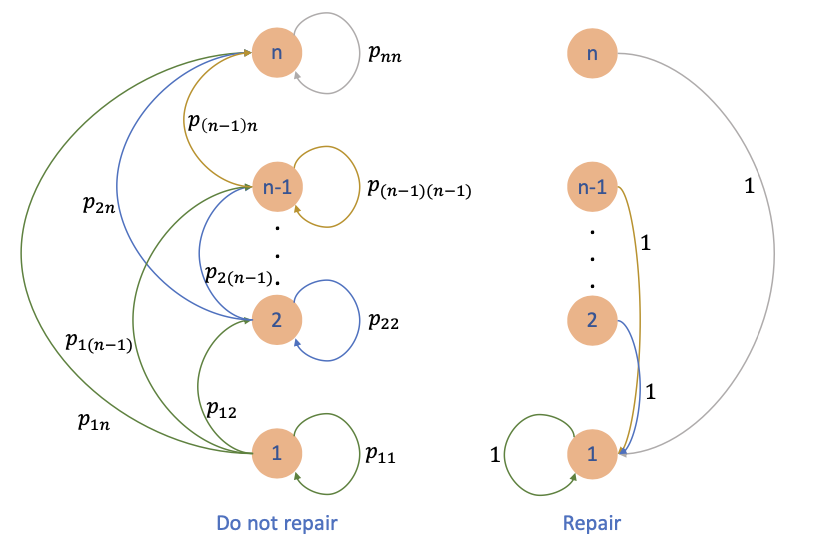
示例:机器维护问题
考虑 N 周期问题,机器可能处于 n 种状态之一:
-
g(i):状态 i 下每周期的运行成本,满足 g(1)≤g(2)≤⋯≤g(n)(状态 i 效率高于 i+1)
-
状态转移概率:
pij=P(下一状态为 j∣当前状态为 i),且 pij=0(若 j<i)
-
每周期初可选择:
- 继续运行:按转移概率演化
- 维修机器:支付成本 R 使状态重置为 1(并在该周期保持状态 1)
库存控制问题
通过每阶段订购物品满足随机需求:
-
xk:第 k 周期初可用库存
-
uk:第 k 周期初订购并交付的库存量
-
wk:第 k 周期随机需求(给定概率分布)
-
r(⋅):库存过剩/缺货的惩罚成本函数
-
c:单位订购成本
总成本函数:
gk(xk,uk,wk)=c⋅uk+r(xk+uk−wk)
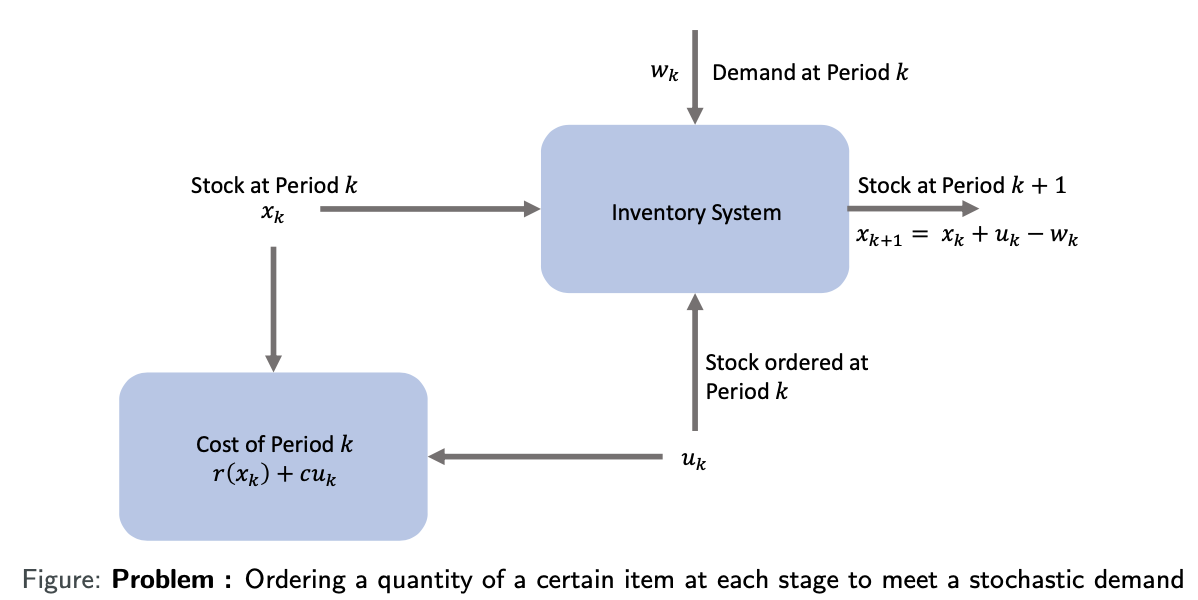
例子:最优解分析
假设 (u0⋆,u1⋆,…,uN−1⋆) 是以下优化问题的最优解:
minE[R(xN)+k=0∑N−1(r(xk+uk−wk)+c⋅uk)]
若需求 w1=w2=⋯=wN−1=0 时
(即第1至第N-1周期需求恒为零)
关键结论
原随机最优解 {uk⋆} 非全局最优,可通过动态调整策略进一步优化成本
原因分析
-
信息价值未被利用
原解基于需求随机性设计,未利用"后续需求为零"的确定性信息
-
库存成本可优化
-
当已知后续无需求时,可减少早期订购量避免库存积压
-
延迟订购决策至必要时刻,降低库存持有成本
例:原方案在周期1大量备货,但实际后续需求为零,导致不必要库存成本
3. 动态调整优势
采用状态反馈策略:
uk∗=πk(xk)
根据实时库存 xk 动态调整订购量,比固定序列 {uk⋆} 更优
开环控制与闭环控制
开环控制 (Open-loop Control)
在初始时刻 k=0,给定初始状态 x0,寻找最优控制序列 (u0⋆,u1⋆,…,uN−1⋆) 以最小化期望总成本:
-
决策方式:所有决策在初始时刻一次性确定
-
数学表示:
u0,…,uN−1minE[k=0∑N−1gk(xk,uk,wk)+gN(xN)]
闭环控制 (Closed-loop Control)
在每个时刻 k,基于当前状态信息 xk 实时做出决策(例如在时间 k 的订购决策):
闭环控制 (Closed-loop Control)
核心概念
uk=μk(xk)
π=μ0,μ1,…,μN−1
Jπ(x0)=E[gN(xN)+k=0∑N−1gk(xk,μk(xk),wk)]
可行策略 (Admissible Policy)
策略 π={μ0,…,μN−1} 称为可行策略当且仅当满足:
μk(xk)∈Uk(xk),∀xk∈Sk, ∀k=0,1,…,N−1
即每个时刻 k 的每个可能状态 xk,控制量 uk 必须属于允许控制集 Uk(xk)。
特性分析
| 特性 |
说明 |
| 实时性 |
控制决策基于当前状态实时生成 |
| 适应性 |
自动响应系统状态变化和外部扰动 |
| 计算复杂度 |
需为所有可能状态设计控制律,计算开销较大 |
| 最优性保证 |
在随机环境下优于开环控制 |
| 实现要求 |
需要完整的实时状态观测系统 |
总结
定义
考虑函数 J∗,定义为:
J∗(x0)=π∈ΠminJπ(x0),∀x0∈S0
其中:
称 J∗ 为最优值函数(optimal value function)。
关键特性
-
全局最优性
J∗ 给出了从任意初始状态 x0 出发的最小可能期望代价
-
策略无关性
与具体策略无关,表示理论上的性能极限
-
基准作用
任何可行策略 π 都满足:
Jπ(x0)≥J∗(x0),∀x0∈S0
计算意义
动态规划算法(DP)
最优性原理 (Principle of Optimality)
定理表述
设 π∗={μ0∗,μ1∗,…,μN−1∗} 是基本问题的最优策略,且在采用 π∗ 时,系统在时刻 i 以正概率到达状态 xi。考虑以下子问题:
minE[gN(xN)+k=i∑N−1gk(xk,μk(xk),wk)]
(即从时刻 i 状态 xi 开始最小化剩余代价)
则截断策略 {μi∗,μi+1∗,…,μN−1∗} 是该子问题的最优策略。
###course information# 核心内涵
-
分段构造:最优策略可通过分段方式构造
-
尾部优先:首先求解尾部子问题(从最终阶段开始)
-
逆向扩展:逐步向前扩展至原始问题
-
最优策略的遗传性
全局最优策略的任意后续片段,对其起始状态而言也是最优的
-
时间一致性
最优决策不仅考虑当前代价,还考虑后续状态的最优演化路径
-
逆向求解基础
该原理保证了动态规划逆向归纳法的有效性
动态规划算法 - 库存控制示例
例子
尾部子问题求解流程
核心思想:逆向求解,从最终阶段逐步向前递推
-
长度1的尾部问题(时刻 k=N−1)
-
决策目标:最小化当期成本与终端成本期望值
minimizec⋅uN−1+EwN−1[R(xN)]
- c⋅uN−1:当期订购成本
- EwN−1[R(xN)]:终端库存成本的期望值
-
状态转移关系:xN=xN−1+uN−1−wN−1
⇒minimizec⋅uN−1+EwN−1[R(xN−1+uN−1−wN−1)]
-
值函数计算:
JN−1(xN−1)=r(xN−1)+uN−1≥0min{c⋅uN−1+EwN−1[R(xN−1+uN−1−wN−1)]}
- r(xN−1):当期库存持有/缺货成本
- 需为所有 xN−1∈SN−1 计算该值函数
-
长度2的尾部问题(时刻 k=N−2)
-
决策目标:最小化当期成本与后续成本期望值
minimizer(xN−2)+c⋅uN−2+EwN−2[JN−1(xN−1)]
-
状态转移关系:xN−1=xN−2+uN−2−wN−2
⇒minimizer(xN−2)+c⋅uN−2+EwN−2[JN−1(xN−2+uN−2−wN−2)]
-
值函数计算:
JN−2(xN−2)=r(xN−2)+uN−2≥0min{c⋅uN−2+EwN−2[JN−1(xN−2+uN−2−wN−2)]}
-
通用递推公式(长度 N−k 的尾部问题)
Jk(xk)=r(xk)+uk≥0min{c⋅uk+Ewk[Jk+1(xk+uk−wk)]}
- r(xk):k 时刻库存成本
- c⋅uk:k 时刻订购成本
- Ewk[Jk+1(⋅)]:后续最优成本的期望
最终目标:通过 k=0 时的尾部问题(长度 N)获得原问题最优解
动态规划算法 (The DP Algorithm)
对于任意初始状态 x0,基本问题的最优成本 J∗(x0) 等于 J0(x0),由以下逆向算法(从 N−1 到 0)给出:
边界条件:
JN(xN)=gN(xN)
递推关系:
Jk(xk)=uk∈Uk(xk)minEwk[gk(xk,uk,wk)+Jk+1(fk(xk,uk,wk))](⋆)
其中期望 Ewk 针对 wk 的概率分布(依赖于 xk 和 uk)。若 uk⋆=μk⋆(xk) 使 (⋆) 式右端最小化,则策略 π⋆={μ0⋆,…,μN−1⋆} 是最优的。
关键定义
算法证明(非正式)
基本设定
-
定义子策略 πk={μk,μk+1,…,μN−1}
-
设 Jk⋆(xk) 为从 (xk,k) 开始的 (N−k) 阶段最优成本:
Jk⋆(xk)=πkminEwk,…,wN−1[gN(xN)+i=k∑N−1gi(xi,μi(xi),wi)]
-
边界条件:
- k=0 时:J0⋆ 是原问题最优值函数
- k=N 时:JN⋆=gN(xN)
归纳证明
目标:证明 Jk⋆=Jk(DP算法值)
-
归纳基础:k=N 时成立(JN⋆=gN(xN)=JN)
-
归纳假设:假设 ∀xk+1∈Sk+1,有 Jk+1⋆(xk+1)=Jk+1(xk+1)
-
推导过程:
Jk⋆(xk)=(μk,πk+1)minEwk,…,wN−1[gN(xN)+i=k∑N−1gi(xi,μi(xi),wi)]=(μk,πk+1)minE[gk(xk,μk(xk),wk)+gN(xN)+i=k+1∑N−1gi(⋯)]=μkminEwk[gk(xk,μk(xk),wk)+πk+1minEwk+1,…,wN−1[gN(xN)+i=k+1∑N−1gi(⋯)]](最优性原理)=μkminEwk[gk(xk,μk(xk),wk)+Jk+1⋆(fk(xk,μk(xk),wk))]=μkminEwk[gk(xk,μk(xk),wk)+Jk+1(fk(xk,μk(xk),wk))](由归纳假设)=ukminEwk[gk(xk,uk,wk)+Jk+1(fk(xk,uk,wk))]=Jk(xk)
动态规划算法 - 烘焙示例
问题描述
博士需用两个烤箱烘焙蛋糕,系统动态和成本函数如下:
-
状态方程:xk+1=(1−a)⋅xk+a⋅uk,k=0,1
-
成本函数:r⋅(x2−T)2+u02+u12
-
参数说明:
- xk:蛋糕在第 k 个烤箱出口的温度
- uk:第 k 个烤箱的设定温度
- a∈(0,1):热传导系数
- T:目标温度
- r>0:终端温度偏差的惩罚系数
动态规划求解过程
-
终端时刻 (k=2)
J2(x2)=r⋅(x2−T)2
-
时刻 k=1
J1(x1)=u1min[u12+J2(x2)]=u1min[u12+r⋅((1−a)x1+au1−T)2]
优化求解:
-
对 u1 求导并令导数为零:
0=2u1+2ra((1−a)x1+au1−T)
-
解得最优控制:
u1∗=1+ra2ra(T−(1−a)x1)
-
代入得值函数:
J1(x1)=1+ra2r((1−a)x1−T)2
-
初始时刻 (k=0)
J0(x0)=u0min[u02+J1(x1)]=u0min[u02+1+ra2r((1−a)2x0+(1−a)au0−T)2]
优化求解:
-
类似求导过程得最优控制:
u0∗=1+ra2(1+(1−a)2)r(1−a)a(T−(1−a)2x0)
-
值函数:
J0(x0)=1+ra2(1+(1−a)2)r((1−a)2x0−T)2
关键结论:
此线性二次型问题可获得解析解,但大多数动态规划问题需数值求解
动态规划算法 - 库存控制示例
问题设定
-
需求处理:未满足需求直接丢失
-
状态转移:xk+1=max{0,xk+uk−wk}
-
控制约束:xk+uk≤2
-
成本结构:
- 订购成本:uk(每单位成本为1)
- 持有成本:(xk+uk−wk)2
- 终端成本:gN(xN)=0
-
需求分布:
P(wk=0)=0.1, P(wk=1)=0.7, P(wk=2)=0.2
-
初始状态:x0=0, N=3
逆向求解过程
需要注意,由于此时 uk 为随机分布,因此计算得到的 Jk 为数学期望。
-
终端时刻 (k=3)
J3(x3)=gN(xN)=0(∀x3)
-
时刻 k=2(倒数第一阶段)
状态空间:x2∈{0,1,2}
-
x2=0:
J2(0)=u2∈{0,1,2}minEw2[u2+(0+u2−w2)2]=min⎩⎨⎧u2=0:u2=1:u2=2:0+0.1(0)2+0.7(−1)2+0.2(−2)2=1.51+0.1(1)2+0.7(0)2+0.2(−1)2=1.32+0.1(4)+0.7(1)+0.2(0)=3.1=1.3(u2∗=1)
-
x2=1:
J2(1)=u2∈{0,1}minEw2[u2+(1+u2−w2)2]=min{u2=0:u2=1:0+0.1(1)2+0.7(0)2+0.2(−1)2=0.31+0.1(4)+0.7(1)+0.2(0)=2.1=0.3(u2∗=0)
-
x2=2:
J2(2)=u2∈{0}minEw2[u2+(2+u2−w2)2]=0+0.1(4)+0.7(1)+0.2(0)=1.1(u2∗=0)
值函数总结:
| x2 |
J2(x2) |
μ2∗(x2) |
| 0 |
1.3 |
1 |
| 1 |
0.3 |
0 |
| 2 |
1.1 |
0 |
-
继续求解 (k=1,0)
类似方法计算 J1(x1) 和 J0(x0),需考虑状态转移:
xk+1=max{0,xk+uk−wk}
计算复杂度分析
-
状态空间:∣Sk∣=3(本例)
-
控制空间:∣Uk∣≤3(本例)
-
时间复杂度:O(N⋅∣S∣⋅∣U∣⋅∣W∣)
-
实际挑战:状态空间随维度指数增长(维度灾难)
动态规划算法 - 有限状态系统
系统描述
考虑具有以下特性的有限状态系统:
-
状态转移概率:pij(u)=P(xk+1=j∣xk=i,uk=u)
-
动态方程:xk+1=wk,其中 wk 服从由 pij(u) 定义的概率分布
关键假设
-
平稳性:
- 转移概率 pij(u) 与时间 k 无关
- 控制约束集 Uk(i)=U(i) 恒定
-
成本特性:
- 阶段成本 g(i,u) 独立于随机扰动 wk
动态规划算法
递推公式:
Jk(i)=u∈U(i)min[g(i,u)+E[Jk+1(wk)]]
显式形式:
Jk(i)=u∈U(i)min[g(i,u)+j∑pij(u)Jk+1(j)]
计算特性
| 特性 |
说明 |
| 状态空间 |
有限(i∈{1,2,…,n}) |
| 控制空间 |
有限(u∈U(i)) |
| 复杂度 |
$O(N \cdot n^2 \cdot |
| 优势 |
避免连续状态空间的维度灾难 |
应用场景:马尔可夫决策过程(MDP)、排队系统、网络路由等离散状态问题
状态增强与系统重构技术
1. 时间滞后处理
问题:当状态转移依赖历史状态(如 xk+1=fk(xk,xk−1,uk,uk−1,wk))
解决方案:状态增强
定义新状态向量:
x~k=xkyksk=xkxk−1uk−1
新状态转移方程:
x~k+1=xk+1yk+1sk+1=fk(xk,yk,uk,sk,wk)xkuk=f~k(x~k,uk,wk)
关键点:将历史状态 xk−1 和历史控制 uk−1 作为当前状态的一部分
2. 相关干扰处理
问题:扰动项相关(如 wk=λwk−1+ξk)
解决方案:状态增强
定义新状态向量:
x~k=[xkyk]其中yk=wk−1
新状态转移方程:
x~k+1=[xk+1yk+1]=[fk(xk,uk,λyk+ξk)λyk+ξk]=f~k(x~k,uk,ξk)
推广形式:对 wk=Ckyk+1, yk+1=Akyk+ξk:
x~k+1=[fk(xk,uk,Ck(Akyk+ξk))Akyk+ξk]
3. 预测信息整合
问题:决策前已知扰动分布信息(如天气预报影响需求分布)
建模:
-
wk∼Qi (i∈{1,…,m})
-
i 在决策 uk 前已知
-
预测过程:yk+1=ξk (ξk 独立,P(ξk=i)=pi)
增强状态:
x~k=[xkyk]
其中 yk 存储下一时刻扰动分布信息
状态转移:
x~k+1=[xk+1yk+1]=[fk(xk,uk,wk)ξk]
决策优势:uk 可基于 yk(未来扰动分布)优化决策
