N : the horizon or number of times control is applied
xk : the state of the system, from the set of states Sk
uk : the control/decision variable/action to be selected from the set Uk (xk ) at time k
wk : a random parameter (also called disturbance)
fk : a function that describes how the state is updated
Assumption wk ’s are independent. The probability distribution may depend on xk and uk .
The Cost Function
The (expected) cost has the form
E[gN(xN)+k=0∑N−1gk(xk,uk,wk)]
where
gk(xk,uk,wk) : the cost incurred at time k.
gN(xN) : the terminal cost incurred at the end of process.
Note
Because of wk , the cost is a random variable and so we are optimizing over the expectation.
A Deterministic Scheduling Problem
Example
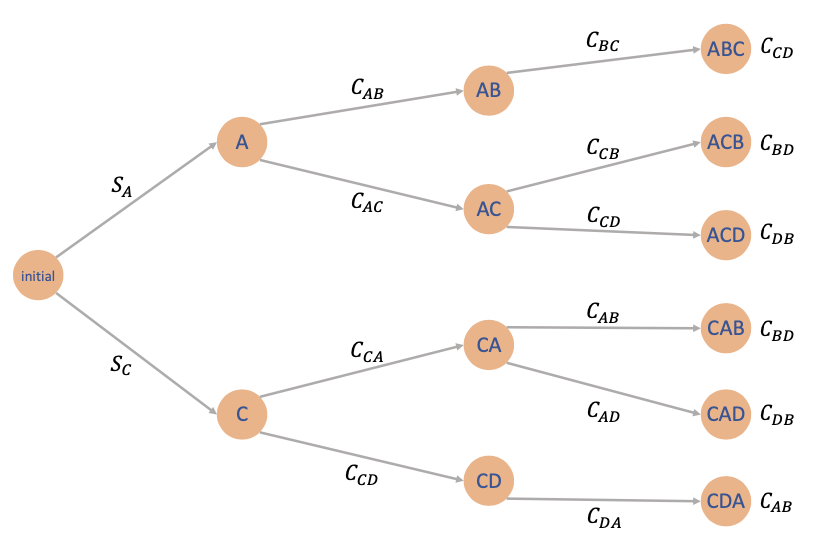
Prof wants to produce luxury headphones that perform better than the bear-pods 3 that he is currently using. To do so, four operations must be performed on a certain machine, and they are denoted by A, B, C, D. Assuming that
operation B can only be performed after operation A
operation D can only be performed after operation C
Denote
setup cost Cmn for passing any operation m to n
initial startup cost SA or SC (can only start with operation A or C)
Solution
We need to make three decisions (the last is determined by the first three)
This problem is deterministic (no wk )
This problem has finite number of states
Deterministic problems with finite number of states => transition graph
Discrete-State and Finite-State Problems
To capture the transition between states, it is often convenient to define the transition probabilities
pij(u,k)=P(xk+1=j∣xk=i,uk=u)
In the dynamic system, it means that xk+1=wk, where wk follows a probabilitydistribution which has probabilities pij(u,k)'s.
Example
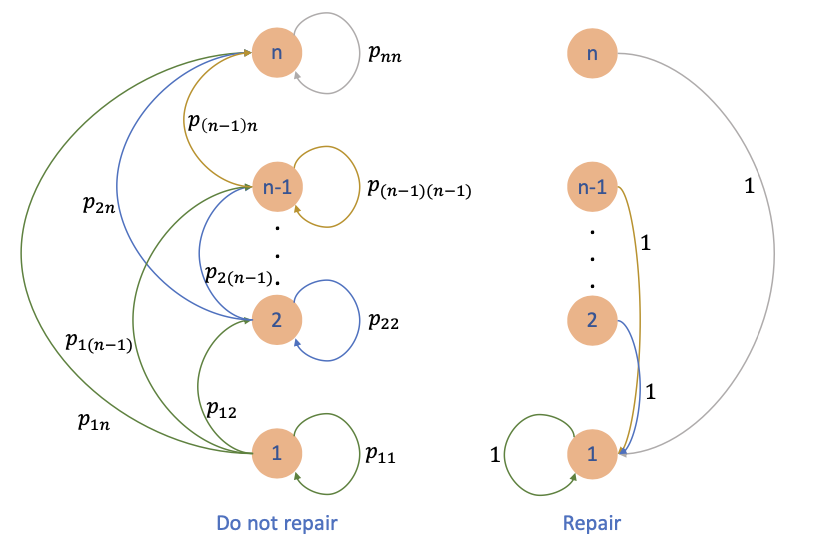
Consider a problem of N time periods that a machine can be in any one of n states. We denote g(i) as the operating cost per period when the machine is in state i. Assume that
g(1)≤g(2)≤⋅⋅⋅≤g(n)
That is, a machine in state i works more efficiently than a machine that is in state i + 1. During a period of time, the state of the machine can become worse or stay the same with probability
pij=P(next state will be j∣current state is i) and pij=0,ifj<i.
At the start of each period, we can choose
let the machine operate one more period
repair the machine and bring it to state 1 (and it will stay there for 1 period) at a cost R
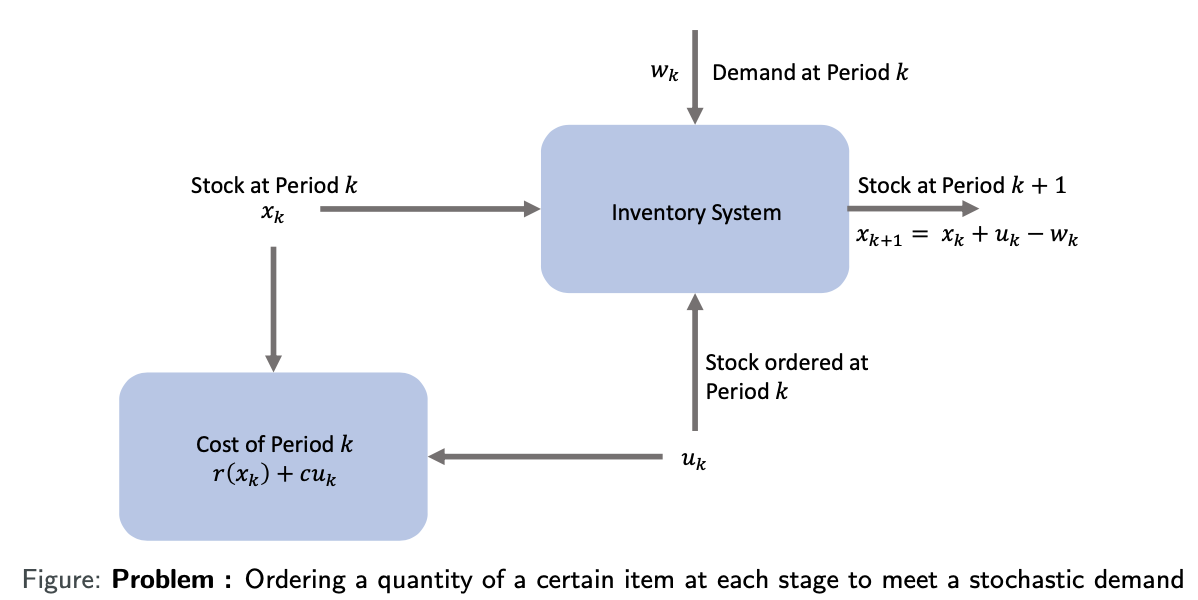
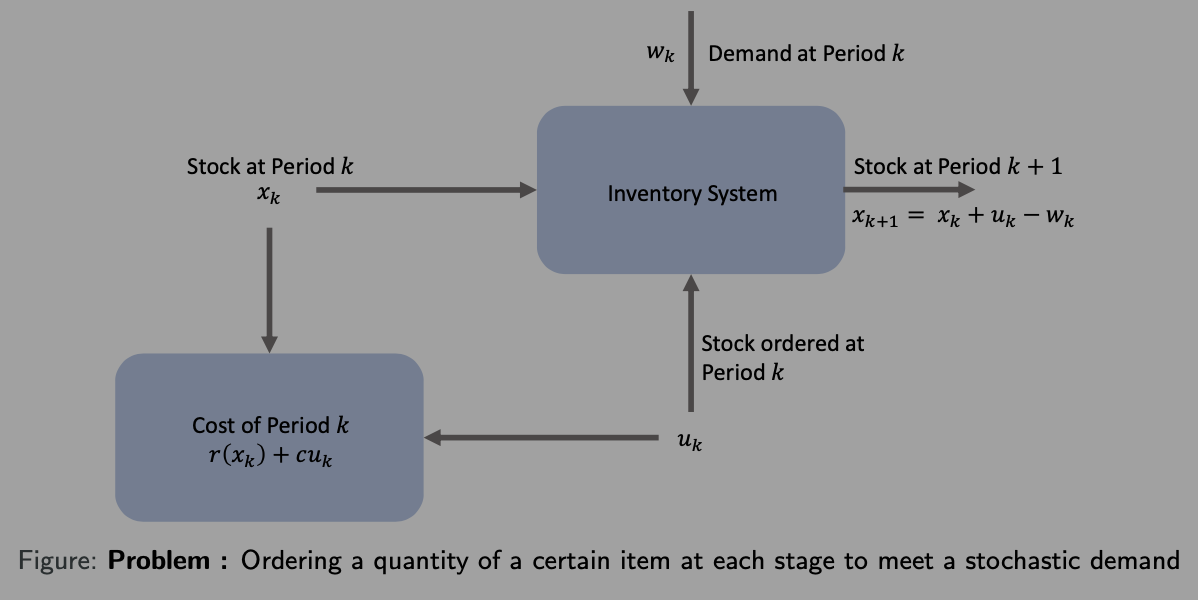
Inventory Control Problem
Ordering a quantity of a certain item at each stage to meet a stochastic demand
xk: stock available at the beginning of the kth period
uk: stock ordered and delivered at the beginning of the kth period
wk: demand during the kth period with given probability distribution
r(⋅): penalty/cost for either positive or negative stock
c: cost per unit ordered
Expample: Inventory Control
Suppose (u0⋆,u1⋆,…,uN−1⋆) is the optimal solution of
minE[R(xN)+k=0∑N−1(r(xk+uk−wk)+c⋅uk)]
What if:w1=w2=⋯=wN−1=0? (recall wi’s are the demands.)
We can do better if we can adjust our decisions to different situations!
Open-Loop and Closed-Loop Control
Open-loop Control
At initial time k=0, given initial state x0, find optimal control sequence (u0⋆,u1⋆,…,uN−1⋆) minimizing expected total cost:
Key feature: Subsequent state information is NOT used to adjust control decisions
Closed-loop Control
At each time k, make decisions based on current state information xk (e.g. ordering decision at time k):
Core objective: Find state feedback strategy μk(⋅) mapping state xk to control uk
Decision characteristics:
Re-optimization at each decision pointk
Control rule designed for every possible state valuexk
Computational properties:
Higher computational cost (requires real-time state mapping)
Same performance as open-loop when no uncertainty exists
Closed-loop Control
Core Concepts
Control Law Definition
Let μk(⋅) be a function mapping state xk to control uk:
uk=μk(xk)
Control Policy
Define a policy π as a sequence of control laws:
π=μ0,μ1,…,μN−1
Policy Cost Function
Given initial state x0, the expected cost of policy π is:
A policy π={μ0,…,μN−1} is called admissible if and only if:
μk(xk)∈Uk(xk),∀xk∈Sk,∀k=0,1,…,N−1
Meaning at each time k and for every possible state xk, the control uk must belong to the allowable control set Uk(xk).
Summary
Definition
Consider a function J∗ defined as:
J∗(x0)=π∈ΠminJπ(x0),∀x0∈S0
where:
Π: Set of all admissible policies
Jπ(x0): Expected cost of policy π starting from initial state x0
We call J∗ the optimal value function.
Key Properties
Global Optimality J∗ gives the minimum possible expected cost from any initial state x0
Policy Independence
Represents theoretical performance limit, independent of specific policies
Benchmarking Role
Any admissible policy π satisfies:
Jπ(x0)≥J∗(x0),∀x0∈S0
Computational Significance
Core Objective of DP: Compute J∗ exactly via backward induction
Control Engineering Application: Measure gap between actual policies and theoretical optimum
The Dynamic Programming Algorithm
Principle of Optimality
Theorem Statement
Let π∗={μ0∗,μ1∗,…,μN−1∗} be an optimal policy for the basic problem. Suppose when using π∗, the system reaches state xi at time i with positive probability. Consider the subproblem starting from (xi,i):
minE[gN(xN)+k=i∑N−1gk(xk,μk(xk),wk)]
Then the truncated policy {μi∗,μi+1∗,…,μN−1∗} is optimal for this subproblem.
Core Implications
Piecemeal Construction: Optimal policy can be constructed in piecemeal fashion
Tail First: First solve the “tail subproblem” (starting from final stage)
Sequential Extension: Extend sequentially to the original problem
Heritability of Optimality
Any tail portion of a globally optimal policy remains optimal for its starting state
Time Consistency
Optimal decisions account for both immediate cost and optimal future state evolution
Foundation for Backward Induction
This principle validates the dynamic programming backward solution approach.
DP Algorithm - Inventory Control Example
Example
Tail Subproblem Solving Process
Core idea: Backward solution from final stage to initial stage
Length-1 Tail Subproblem (at k=N−1)
Decision Objective: Minimize current cost + terminal cost expectation
The expectation Ewk is over wk’s probability distribution (dependent on xk and uk). If uk⋆=μk⋆(xk) minimizes the RHS of (⋆), then π⋆={μ0⋆,…,μN−1⋆} is optimal.
Key Definitions
Jk(xk): Cost-to-go at state xk and time k
Jk: Cost-to-go function at time k
Algorithm Proof (Informal)
Setup
Define subpolicy πk={μk,μk+1,…,μN−1}
Let Jk⋆(xk) be optimal cost for (N−k)-stage starting at (xk,k):
Jk⋆(xk)=(μk,πk+1)minEwk,…,wN−1[gN(xN)+i=k∑N−1gi(xi,μi(xi),wi)]=(μk,πk+1)minE[gk(xk,μk(xk),wk)+gN(xN)+i=k+1∑N−1gi(⋯)]=μkminEwk[gk(xk,μk(xk),wk)+πk+1minEwk+1,…,wN−1[gN(xN)+i=k+1∑N−1gi(⋯)]](Principle of Optimality)=μkminEwk[gk(xk,μk(xk),wk)+Jk+1⋆(fk(xk,μk(xk),wk))]=μkminEwk[gk(xk,μk(xk),wk)+Jk+1(fk(xk,μk(xk),wk))](by Induction Hypothesis)=ukminEwk[gk(xk,uk,wk)+Jk+1(fk(xk,uk,wk))]=Jk(xk)
DP Algorithm - Baking Example
Problem Description
Dr. Yang bakes a cake using two ovens with dynamics and cost: