#sdsc6015
English / 中文
点击展开 Mirror Descent 复习内容
考虑单纯形约束优化问题:
x∈△dminf(x)
其中单纯形 △d:={x∈Rd:∑i=1dxi=1,xi≥0,∀i}。假设梯度无穷范数有界:∥∇f(x)∥∞=maxi=1,…,d∣[∇f(x)]i∣≤1。
迭代格式:
yt+1=∇Φ∗(∇Φ(xt)−ηgt),xt+1=ΠXΦ(yt+1)
其中 gt∈∂f(xt),Φ 是镜像势能,ΠXΦ 是基于 Bregman 散度的投影。
-
符号说明:Φ 严格凸、连续可微,DΦ(x,y) 是 Bregman 散度。
-
几何意义:通过势能函数将问题变换到对偶空间,使更新方向更贴合几何结构。
定理 1(Mirror Descent 收敛性):
设 Φ 是 ρ-强凸镜像映射,R2=supx∈XΦ(x)−Φ(x1),f 凸且 L-Lipschitz。取 η=L2RTρ,则:
t=1,…,TminE[f(xt)]−f(x∗)≤2RLρT1
证明概要
1. 利用 Bregman 散度的强凸性 bound 误差。
2. 通过梯度 Lipschitz 性控制项。
3. 求和并优化步长。
详细见文档1第9页。
-
球设置:Φ(x)=21∥x∥22,等价于投影梯度下降。
-
单纯形设置:Φ(x)=∑i=1dxilogxi(负熵),Bregman 散度为 KL 散度,投影通过重归一化实现。
-
例子:在单纯形上优化概率分布时,Mirror Descent 自然处理约束,避免欧氏投影偏差。
随机梯度下降(Stochastic Gradient Descent, SGD)
问题形式
主问题定义为最小化一个函数 f(θ),其中 θ∈Rd 是参数向量。具体形式如下:
θ∈Rdminimizef(θ)
这里,f(θ) 通常是一个期望损失函数,表示为:
f(θ)=∫ℓ(θ,Z)dP(Z)
-
Z∈Rp 是一个随机变量,代表数据点(如特征和标签)。
-
P(Z) 是未知的分布,这反映了在现实问题中数据分布往往不可知,只能通过样本估计。
-
ℓ(θ,Z) 是损失函数,参数化 by θ,用于衡量模型在数据点 Z 上的性能。
核心:通过最小化期望损失来学习参数 θ,但由于 P(Z) 未知,实际中我们使用经验风险最小化,即用样本均值近似积分。
给定一组带标签的训练数据 (x1,y1),…,(xn,yn)∈Rd×Y,目标是找到权重参数 θ 来对数据进行分类。这连接了优化问题与监督学习任务,如分类或回归。
简单来说,主问题就是通过优化参数 θ 来最小化模型在所有可能数据上的平均损失,但由于分布未知,我们依赖有限样本。
动机
当数据量巨大时(例如 n≫1,000,000),计算全梯度变得不切实际。具体分析如下:
-
定义 fi(θ)=ℓ(θ,(xi,yi)) 为第 i 个观测值的成本函数,取自包含 n 个观测的训练集。
-
全梯度 ∇f(θ)=∑i=1n∇fi(θ) 需要遍历所有数据点,计算成本随 n 线性增长,当 n 极大时,这会导致计算瓶颈。
-
因此,可以使用更便宜的方法:计算单个组件梯度 ∇fi(θ) 或小批量(batch)梯度。这引入了随机梯度下降(SGD)或其变种,通过随机采样数据点子集来近似梯度,从而大幅降低每次迭代的计算量。
SGD 算法描述
随机梯度下降的基本步骤如下:
-
初始化:设置初始点 x0∈Rd。
-
迭代过程:对于每个时间步 t=0,1,…:
- 随机均匀采样一个索引 it∈{1,2,…,n}。
- 更新参数: xt+1=xt−ηt∇fit(xt),其中 ηt 是学习率。
这里,gt:=∇fit(xt) 被称为随机梯度,它仅使用单个函数组件 fit 的梯度,而不是全梯度 ∇f(xt)=n1∑i=1n∇fi(xt)。
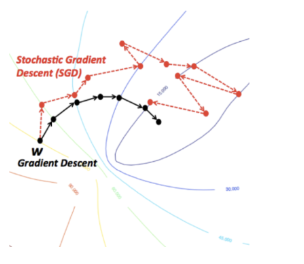
优点:计算效率
- 每次迭代只计算一个函数组件的梯度,因此迭代成本比全梯度下降(Full Gradient Descent)低 n 倍。
- 这使得SGD在处理大数据集时更具可扩展性。
收敛性考虑
尽管SGD计算高效,但使用单个组件的梯度不一定保证收敛。文档中给出了一个例子来说明这个问题:
示例:考虑优化问题 minxf(x)=f1(x)+f2(x),其中 f1(x)=x2 和 f2(x)=−x2。如果从 xk>0 开始,且随机采样到 ik=2,则梯度更新 xk+1=xk−ηt∇f2(xk) 可能导致函数值增加(因为 ∇f2(x)=−2x,更新方向可能朝错误方向)。
然而,SGD在期望上可以产生下降,这引出了无偏性的概念。
无偏性(Unbiasedness)
随机梯度 gt 是真实梯度 ∇f(xt) 的无偏估计,即:
E[gt∣xt=x]=∇f(xt)
其中期望是对随机索引 it 取的。
意义:无偏性确保在平均意义下,SGD的更新方向是正确的。尽管单个步骤可能随机偏离,但长期来看,算法会朝着最优解收敛。这允许我们使用期望不等式来分析收敛性,而不是依赖凸性等强假设。
条件期望
条件期望详解:
定义
条件期望是概率论和统计学中的核心概念,用于在已知部分信息(如另一个随机变量的值)下,对随机变量进行近似估计。
说明:条件期望在机器学习中常用于处理部分观测数据,例如在随机梯度下降中优化模型参数。
性质
-
线性性:条件期望是线性的,即对于随机变量 X 和 Y,以及常数 a 和 b,有:
E[aX+bY∣Z]=aE[X∣Z]+bE[Y∣Z]
文档中暗示了类似性质,例如对于 Z = X + Y 或 Z = XY,条件期望可能满足加法或乘法规则,但具体公式未给出。
-
Partition Theorem(分割定理):针对离散随机变量 Y,该定理提供了计算期望的简化方法。
示例:假设 Y 是离散的(如分类变量),则 E[X] 可以通过对 Y 的每个可能值计算 E[X∣Y=y] 并加权平均得到。
期望的凸性
E[f(X)∣Y]=基于 Y 的线性组合
其中 f 是凸函数。
E[L(xt)]=E[E[L(xt)∣Y]]
其中 L 是损失函数,这有助于证明收敛性。
说明:在随机优化中,这种凸性分析确保算法即使在噪声数据下也能稳定收敛。
总结
文档重点介绍了条件期望的定义、性质(如线性性和 Partition Theorem)及其在凸性分析中的应用。这些概念是随机优化和机器学习的基础,有助于处理不确定性和部分信息。条件期望作为“最佳近似”工具,在模型训练和收敛证明中发挥关键作用。
注意:文档中提及的图片标签(如 ``)由于具体内容未提供,且为避免虚构,未在总结中嵌入。总结严格基于文本内容。
收敛定理
定理 2(凸函数上的 SGD):
设 f 凸可微,x∗ 是全局最优,∥x0−x∗∥≤R,且 E[∥gt∥2]≤B2。取常步长 η=BTR,则:
T1t=0∑T−1E[f(xt)]−f(x∗)≤TRB
证明详情(基于文档2 P23 补充)
证明概要:
-
基础不等式:从迭代规则出发:
∥xt+1−x∗∥2=∥xt−x∗∥2−2ηgt⊤(xt−x∗)+η2∥gt∥2
-
取期望:利用无偏性 E[gt∣xt]=∇f(xt) 和凸性期望:
E[gt⊤(xt−x∗)]=E[∇f(xt)⊤(xt−x∗)]≥E[f(xt)−f(x∗)]
-
求和优化:对 t=0 到 T−1 求和,并代入步长 η=BTR:
t=0∑T−1E[f(xt)−f(x∗)]≤2ηR2+2ηB2T=RBT
-
Jensen 不等式:应用 E[f(xˉT)]≤T1∑t=0T−1E[f(xt)],得最终界。
几何意义:SGD 在期望下沿下降方向移动,但方差导致振荡;步长调节平衡收敛速度和稳定性。
定理 3(强凸函数上的 SGD):
设 f μ-强凸,x∗ 唯一最优,取步长 ηt=μt1,则:
E[∥xT−x∗∥2]≤μ2TB2
证明详情(基于文档2 P26 补充)
证明步骤:
-
强凸性不等式:
f(x∗)≥f(xt)+∇f(xt)⊤(x∗−xt)+2μ∥xt−x∗∥2
-
迭代分析:代入 SGD 更新规则,取期望:
E[∥xt+1−x∗∥2]≤(1−μηt)E[∥xt−x∗∥2]+ηt2B2
-
递推求解:设 ηt=1/(μt),利用递推式求和得收敛界。
几何意义:强凸性确保函数有唯一最小点,SGD 以线性率收敛,但方差项 B2 影响精度。
小批量 SGD(Mini-batch SGD)
使用批量更新:g~t=∣St∣1∑i∈St∇fi(xt),其中 St⊂{1,…,n} 是随机子集。
-
符号说明:∣St∣=m 是批量大小,m=1 等价于 SGD,m=n 等价于 GD。
-
方差计算(文档2 P31 补充):
E[∥g~t−∇f(xt)∥2]=m1E[∥∇f1(xt)−∇f(xt)∥2]≤mB2
当 m→∞,方差趋于零。
-
几何意义:批量平均减少方差,使梯度估计更稳定,但每轮计算成本增加。
随机次梯度下降和约束优化
对于非光滑问题,使用次梯度 gt∈∂fi(xt),更新为 xt+1=xt−ηtgt。约束问题加入投影步骤(Projected SGD),收敛率仍为 O(1/ε2)。
动量方法(Momentum Methods)
动机
GD 在长窄谷形函数上振荡严重。动量方法引入历史步长信息加速收敛。
重球法(Polyak Momentum)
更新规则:
xt+1=xt−ηt∇f(xt)+βt(xt−xt−1)
或等价写为:
vt+1=βtvt−ηt∇f(xt),xt+1=xt+vt+1
其中 βt∈[0,1] 是动量系数。
收敛性
定理 4(二次函数上的收敛):
考虑强凸二次函数 f(x)=21x⊤Qx−b⊤x,其中 Q 正定,条件数 κ=L/μ。取 ηt=(L+μ)24,βt=(κ+1κ−1)2,则重球法以线性率收敛。
证明概要
证明思路:
几何意义:对于二次函数,动量调整步长以匹配 Hessian 矩阵的特征值分布,加速收敛。
Nesterov 加速梯度下降
与重球法类似,但使用预测点计算梯度,理论保证更鲁棒。更新规则差异:
