
SDSC6015 Course 1-Introduction / Preliminaries of Stochastic Optimization
#sdsc6015
English / Chinese
Course Introduction and Preliminary Stochastic Optimization
Main Problem
Given labeled training data ,
find weights to minimize:
Objective: Quantify model prediction error through the loss function and optimize parameters .
Supplementary Notes
Mathematical Notation Explanation:
-
: Parameter vector to optimize (e.g., weights in linear models, neural network parameters)
-
: Loss function, quantifying the discrepancy between model prediction and true label
-
: Empirical risk, representing the average loss over the training set
Practical Significance:
This optimization problem is called Empirical Risk Minimization (ERM):
- Core Idea: Generalize the model to new data by minimizing average loss on the training set
- Challenge: High computational cost for gradient calculation when is extremely large
- Solution: Stochastic optimization algorithms (e.g., SGD) approximate gradients using subsets of data per iteration
Soft Margin Support Vector Machine (SVM)

-
: Feature vector
-
: Class label
-
: Regularization coefficient
-
: Parameters to learn
Hinge Loss: penalizes misclassification.
Regularization: controls model complexity to prevent overfitting.
Supplementary Notes
Mathematical Derivation:
-
Origin of Hinge Loss:
- Ideal constraint (all samples correctly classified with margin ≥1)
- Introduce slack variables to allow constraint violation:
- Minimize violation degree →
Geometric Interpretation: Distance from sample to decision boundary , penalized when
-
Derivation of Regularization Term:
- Margin size
- Maximizing margin is equivalent to minimizing (since )
Practical Meaning: balances classification error and model complexity
- : Allows more misclassification (large margin)
- : Strict classification (small margin)
Extended Notation Explanation:
-
: Decision hyperplane (boundary separating classes)
-
: Normal vector direction (determines classification direction)
-
: Intercept term (adjusts hyperplane position)
Example:
In 2D space:
-
Decision boundary is line
-
Positive class () on one side, negative class () on the other
-
Hinge loss activates only when samples enter the “margin zone” (gray area)
Example: Image Denoising
Total Variation Denoising Model:
-
: Image matrix to recover
-
: Noisy observed image
-
: Set of observed pixel indices
-
: Total variation regularization term:
Data Fidelity Term: ensures recovered image resembles observations.
Smoothness Constraint: promotes piecewise smoothness by penalizing adjacent pixel differences.
Supplementary Notes
Mathematical Derivation:
-
Physical Meaning of :
- computes vertical gradient (intensity difference with lower neighbor)
- computes horizontal gradient (intensity difference with right neighbor)
Core Idea: Natural images exhibit “piecewise smooth” properties (similar adjacent pixels), while noise disrupts continuity
-
Optimization Objective Decomposition:
- Data Fidelity Term: Minimize (squared Frobenius norm) → Maintain similarity to observed image
- Regularization Term: Minimize image gradient (L1 norm of gradient vector) → Promote smoothness
controls smoothness strength: → Smoother but may blur details
Extended Notation Explanation:
-
: Pixel intensity (grayscale value) at position
-
: Discrete gradient operator
-
L1 norm : More robust to noise (compared to L2 norm)
Practical Significance:
Medical Imaging: Remove Gaussian noise in CT scans while preserving organ boundaries
Satellite Imagery: Eliminate cloud interference and restore surface textures
Comparison with Gaussian Filtering: TV denoising preserves edges (e.g., building contours), while Gaussian filtering blurs edges
Example:
Assume 2×2 noisy image :
-
Compute
-
Denoised image has significantly reduced (e.g., 40) while remains small
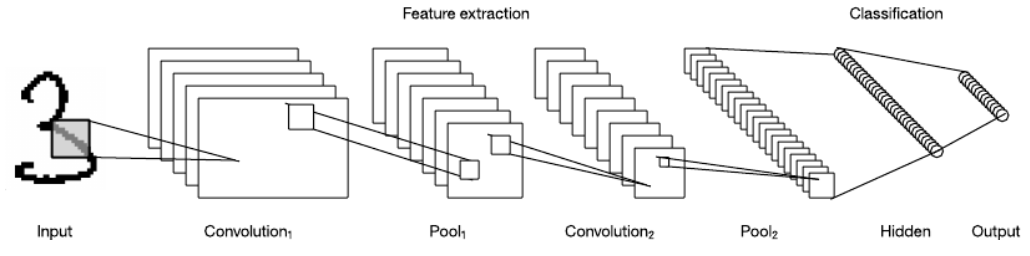
Example: Neural Networks
Convolutional Neural Network (CNN):
where
-
: ReLU activation function
-
: Weight matrices
-
: Bias vectors
-
: Input data, : Target output
ReLU Activation: outputs 0 for negative inputs, introducing nonlinearity.
Hierarchical Structure: Nested transformations model complex feature interactions.
Supplementary Notes
Mathematical Derivation:
-
Forward Propagation Process:
- Input Layer: (raw input, e.g., image pixels)
- Hidden Layer 1: (linear transformation)
(ReLU activation, ) - Hidden Layer 2:
- Output Layer: (predicted value)
computes squared error between prediction and true value
-
Mathematical Properties of ReLU:
Advantages:
- Solves vanishing gradient problem (gradient=1 in positive region)
- Sparse activation (~50% neuron activation)
Extended Notation Explanation:
-
: Weight matrix ( = number of neurons in layer )
-
: Bias vector (shifts decision boundary)
-
: Element-wise operation (applies ReLU independently to each element)
Practical Significance:
Feature Extraction:
- Shallow layers learn edges/textures ()
- Middle layers learn parts/shapes ()
- Deep layers learn semantic concepts ()
Optimization Challenges:
- Non-convex objective (multiple local optima)
- Gradient computation requires backpropagation (chain rule)
Example (Digit Recognition):
Input is 28×28 handwritten digit image ():
-
: Convolutional kernels extract edges (output feature maps)
-
: Retains positive activations (enhances feature contrast)
-
: Combines edges into digit components (e.g., horizontal stroke of “7”)
-
: Combines components into digits 0-9 (output )
Simple Numerical Example: Least Squares Regression
Problem Setup
-
: Data matrix
-
: Observation vector
-
: Variable to optimize
Gradient Descent (GD) vs. Stochastic Gradient Descent (SGD)
| Method | Update Rule | Gradient Calculation | Per-Step Cost |
|---|---|---|---|
| GD | |||
| SGD |
Core Idea:
- GD uses all data points per step → High computation cost but stable convergence.
- SGD uses one random data point per step → Computationally efficient for large-scale data, but noisy convergence.
Simulation Parameters
-
Data: , (, )
-
Step Size:
-
Initial Value:
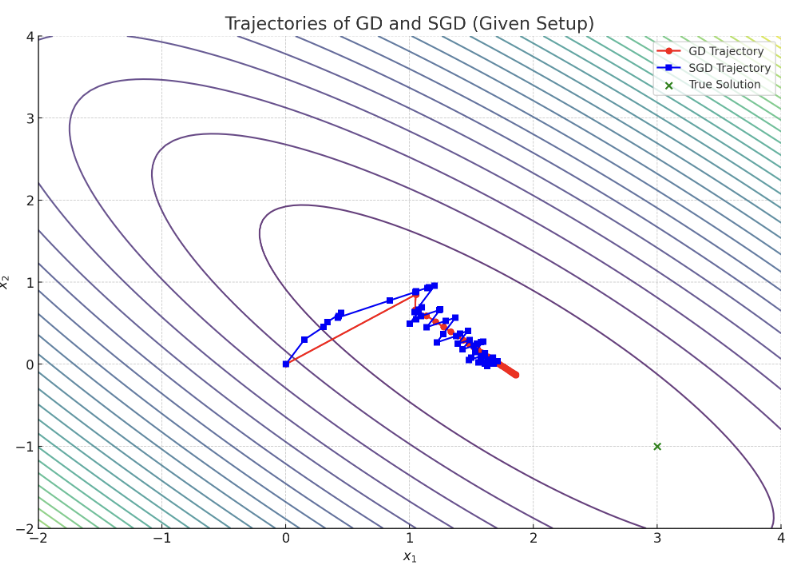

Key Takeaways
GD: Smooth convergence but high per-iteration cost.
SGD: Low per-step cost, practically faster convergence for large-scale problems (despite noisy path).
Preliminaries of Stochastic Optimization
Cauchy-Schwarz Inequality
For any vectors :
Notation Explanation:
-
, : -dimensional real column vectors
-
: Scalar product (inner product)
-
: Euclidean norm
Geometric Interpretation:
- For unit vectors (), equality holds iff or
- Defines vector angle : , satisfying


Hölder’s Inequality
For with , and any vectors :
Related Concepts:
-
-norm:
-
Larger gives higher weight to large components
-
Cauchy-Schwarz is a special case when
Core Idea: Quantify upper bounds on vector interactions via and norms.
Convex Sets
A set is convex iff the line segment between any two points lies within :
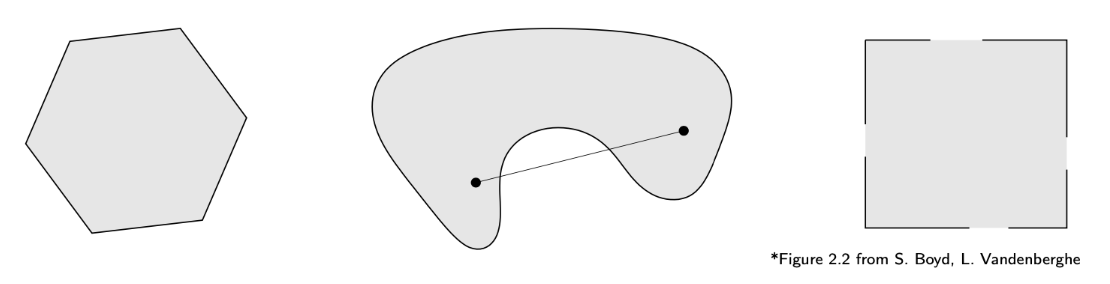
Left: Convex set
Middle: Non-convex set (segment not fully contained)
Right: Non-convex set (missing boundary points)
Properties of Convex Sets
-
Closed under intersection: Intersection of convex sets is convex

-
Unique projection: For non-empty closed convex set , the projection operator has a unique solution
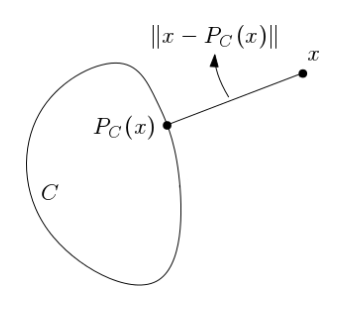
-
Non-expansiveness:

Lipschitz Continuity
A function is -Lipschitz continuous if:
Meaning of : Upper bound on function change rate
Examples: ,
Differentiable Functions
A function is differentiable at if there exists gradient such that:
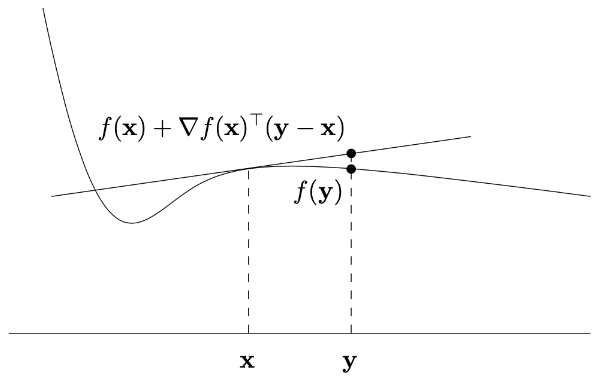
where is a small perturbation. If differentiable everywhere, its graph has a tangent hyperplane at every point.
Non-Differentiable Function Example
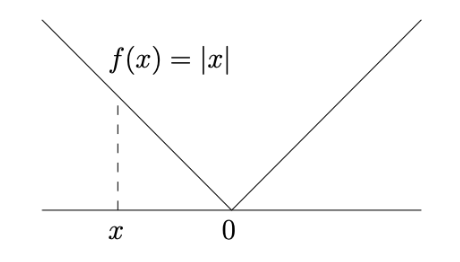
Characteristic: Non-differentiable at origin (“ice cream cone” shape)
L-Smoothness
A function is -smooth if:
-
is continuously differentiable (gradient exists and is continuous)
-
Gradient satisfies -Lipschitz condition:
Gradient Definition:
Example: is -smooth
Supplementary Notes
Mathematical Derivation:
-
Computing Lipschitz Constant:
Maximum secant slope between any two points
-
Lipschitz Condition for Differentiable Functions:
If differentiable,Proof: By mean value theorem
Extended Notation Explanation:
-
: Euclidean distance between points in
-
: Lipschitz constant (upper bound on function change rate)
-
: Absolute value of function change
Practical Significance:
Optimization Algorithm Stability:
- In gradient descent, determines maximum step size ()
- Ensures convergence (prevents oscillation or divergence)
Neural Network Training:
- Lipschitz constraints on weight matrices control model sensitivity
- Enhance adversarial robustness (resist input perturbations)
Example Verification:
-
:
→
-
:
→
-
Non-Lipschitz Function:
→ No global Lipschitz constant
Geometric Interpretation:
Graph of Lipschitz continuous function confined within a “slope cone”
Vertical distance between any two points ≤ horizontal distance
Convex Functions
Definition and Geometric Interpretation
A function is convex if:
-
Domain is convex
-
Satisfies convex inequality:
Geometric Interpretation: The line segment (chord) between any two points on the graph lies above the graph.

Supplementary Notes
Mathematical Notation Explanation:
-
: Interpolation parameter, controlling linear combination ratio
-
: Convex combination, representing a point on the segment connecting and
-
: Function value at convex combination point
-
: Linear interpolation between and
Key Property Derivation:
Convex inequality is equivalent to:
Meaning the average growth rate is non-decreasing in any interval
Practical Significance:
Optimization Advantage: Local minima of convex functions are global minima
Economic Decisions: Model diminishing marginal returns (e.g., production cost functions)
Physical Systems: Spring potential is convex ()
Geometric Properties:
Chord Above Graph:
- For any , the segment connecting and
- Always lies above the function graph
No Local Dips:
- Function curve has no “bowl-shaped” dips (e.g., )
- For twice differentiable functions, equivalent to (Hessian positive semi-definite)
Example Verification:
-
Convex Function:
Difference: → Satisfies convex inequality
-
Non-Convex Function: (on )
Take :
But at , → Violates convex inequality
Metaphorical Understanding:
Imagine convex functions as “valleys”:
- Cable car line (chord) between any two points stays above valley floor (function graph)
- Water droplets sliding down converge to the lowest point (global optimum)
Common Convex Function Examples
-
Linear Function:
-
Affine Function:
-
Exponential Function:
-
Norms: Any norm on (e.g., Euclidean norm )
Proof of Norm Convexity:
By triangle inequality and homogeneity :
Relationship Between Convex Functions and Sets: Epigraph
Graph of a Function
The graph of a function is defined as:
where denotes the domain of .
Epigraph
The epigraph of a function is:
Note: The epigraph is the set of all points above the function graph, visually the region “above” the function. For convex , the epigraph forms a convex “bowl-shaped” set.
-
Key Property:
is convex is convex
Note: This links function convexity to set convexity, simplifying analysis by leveraging convex set properties (e.g., segments lie within the set).
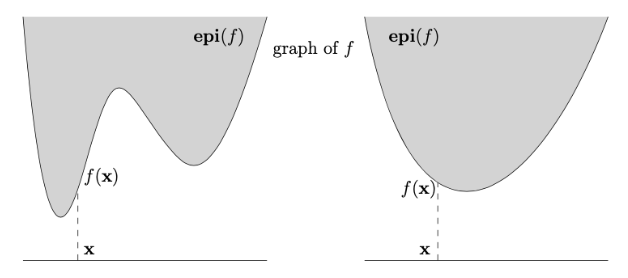
Proof: convex convex
⇒ (Sufficiency): Assume convex. Take any . Prove segment is in , i.e.:
By convexity of () and since imply , , the inequality holds. Thus is convex.
⇐ (Necessity): Assume convex. Take points . Since convex, segment is in , i.e.:
By epigraph definition, , equivalent to . Thus is convex.
Note: Proof uses the epigraph inequality to convert set convexity to function convexity. Part 1 derives set convexity from function convexity, Part 2 reverses.
Jensen’s Inequality
Lemma 1 (Jensen’s Inequality)
Let be convex, , with . Then:
Note:
- For , this reduces to convex function definition.
- General case proven by induction (exercise). Core idea: decompose convex combination recursively.
Geometric Properties of Differentiable Functions
For differentiable , the affine function:
describes the tangent hyperplane to at .
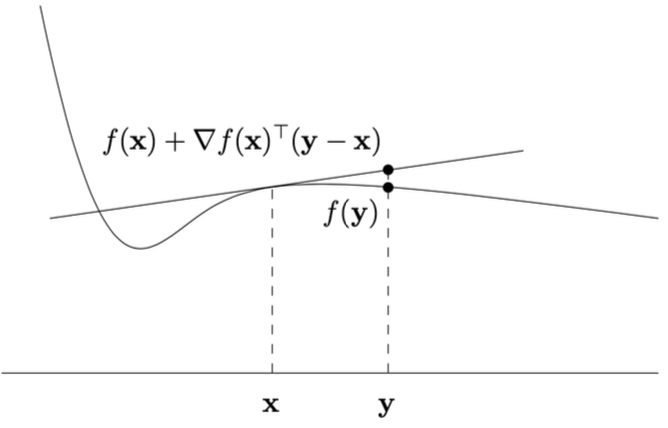
Geometric Interpretation:
- is the gradient (multidimensional derivative) at .
- This tangent hyperplane touches ’s surface at and locally approximates .
- If convex, the tangent hyperplane lies below the entire function graph.
Convexity Criteria
First-Order Convexity Condition
Lemma 2
Assume open and differentiable (gradient exists everywhere). Then convex iff:
-
convex;
-
For all :
Geometric Interpretation:
- Inequality means convex function graph lies above its tangent hyperplane at any point (“bowl-shaped”).
- Gradient is the steepest ascent direction, the steepest descent.
Second-Order Convexity Condition
Assume open and twice differentiable (Hessian symmetric and exists everywhere). Then convex iff:
-
convex;
-
For all , Hessian is positive semi-definite (), i.e.:
Key Concepts:
- Hessian Matrix: Symmetric matrix of second partial derivatives, describing local curvature:
Positive Semi-Definiteness (): Non-negative eigenvalues, indicating “upward curvature” in all directions (e.g., Hessian of is 2).
Example
Hessian of :
Note: This matrix is positive definite (eigenvalues 2 > 0), so is strictly convex (rotational paraboloid).
Properties of Convex Functions
Convexity-Preserving Operations
Lemma 4
(i) Let be convex, . Then is convex on .
Note: Non-negative linear combinations of convex functions remain convex (domain is intersection).
(ii) Let convex (), affine (). Then (i.e., ) is convex on .
Note: Composition with affine mapping preserves convexity (e.g., convex).
Local Minimum is Global Minimum
Definition: is a local minimum of if such that for all with .
Lemma 5: Local minimum of convex is a global minimum (i.e., ).
Proof:
Assume with . Construct (). By convexity:
As , , contradicting being local minimum.
Critical Point is Global Minimum
Lemma 6: If differentiable and convex on open convex set , and (critical point), then is global minimum.
Proof:
By first-order condition (Lemma 2), for any :
Geometric Interpretation: Zero gradient implies horizontal tangent hyperplane and global minimum.
Strictly Convex Functions
Definition: is strictly convex if:
-
convex;
-
For all and :
Examples:
- strictly convex (left);
- Linear functions convex but not strictly convex (right).
Lemma 7: Strictly convex functions have at most one global minimum.
Constrained Minimization
Definition: Let convex, convex. minimizes on if .
Lemma 8: If differentiable on open convex , convex, then is minimum iff:
Geometric Interpretation: At , gradient forms angle with feasible directions (no descent direction).
Existence of Minimum
-Sublevel Set: .
Note: Even if bounded below (e.g., ), minimum may not exist (requires sublevel sets compact).
Convex Optimization Problems
Form:
with convex, convex (e.g., ).
Key Properties:
-
Local minimum is global minimum.
-
Algorithms (coordinate descent, gradient descent, SGD, etc.) provably converge to global optimum.
Convergence Rate Example: Gradient descent converges at rate:
where is optimum, constant (depends on initialization and function properties).