#sdsc6015
English / Chinese
Review - Convex Functions and Convex Optimization
Review
Review
A function f : R d → R f: \mathbb{R}^d \to \mathbb{R} f : R d → R
Its domain dom ( f ) \text{dom}(f) dom ( f )
For all x , y ∈ dom ( f ) \mathbf{x}, \mathbf{y} \in \text{dom}(f) x , y ∈ dom ( f ) λ ∈ [ 0 , 1 ] \lambda \in [0,1] λ ∈ [ 0 , 1 ]
f ( λ x + ( 1 − λ ) y ) ≤ λ f ( x ) + ( 1 − λ ) f ( y ) f(\lambda \mathbf{x} + (1-\lambda)\mathbf{y}) \leq \lambda f(\mathbf{x}) + (1-\lambda)f(\mathbf{y})
f ( λ x + ( 1 − λ ) y ) ≤ λ f ( x ) + ( 1 − λ ) f ( y )
Geometric Interpretation : The line segment between any two points on the function’s graph lies above the graph.
Review
If f f f
f ( y ) ≥ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) , ∀ x , y ∈ dom ( f ) f(\mathbf{y}) \geq f(\mathbf{x}) + \nabla f(\mathbf{x})^\top (\mathbf{y} - \mathbf{x}), \quad \forall \mathbf{x}, \mathbf{y} \in \text{dom}(f)
f ( y ) ≥ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) , ∀ x , y ∈ dom ( f )
Geometric Interpretation : The function graph always lies above its tangent hyperplane.
Review
Definition : f f f x 0 \mathbf{x}_0 x 0 ∇ f ( x 0 ) \nabla f(\mathbf{x}_0) ∇ f ( x 0 )
f ( x 0 + h ) ≈ f ( x 0 ) + ∇ f ( x 0 ) ⊤ h f(\mathbf{x}_0 + \mathbf{h}) \approx f(\mathbf{x}_0) + \nabla f(\mathbf{x}_0)^\top \mathbf{h}
f ( x 0 + h ) ≈ f ( x 0 ) + ∇ f ( x 0 ) ⊤ h
where h \mathbf{h} h
Globally Differentiable : If differentiable at every point in the domain, f f f
Review
Formulation:
min x ∈ R d f ( x ) \min_{\mathbf{x} \in \mathbb{R}^d} f(\mathbf{x})
x ∈ R d min f ( x )
where f f f R d \mathbb{R}^d R d x ∗ = arg min f ( x ) \mathbf{x}^* = \arg\min f(\mathbf{x}) x ∗ = arg min f ( x )
Gradient Descent Method
Core Idea
Update parameters using the negative gradient direction (gradient ∇ f ( x ) \nabla f(\mathbf{x}) ∇ f ( x )
x k + 1 = x k − η k ∇ f ( x k ) \mathbf{x}_{k+1} = \mathbf{x}_k - \eta_k \nabla f(\mathbf{x}_k)
x k + 1 = x k − η k ∇ f ( x k )
where:
x k \mathbf{x}_k x k k k k
η k \eta_k η k η k > 0 \eta_k > 0 η k > 0
∇ f ( x k ) \nabla f(\mathbf{x}_k) ∇ f ( x k ) f f f x k \mathbf{x}_k x k
x k + 1 \mathbf{x}_{k+1} x k + 1
Key Notes :
Gradient Direction : Negative gradient − ∇ f ( x k ) -\nabla f(\mathbf{x}_k) − ∇ f ( x k ) Step Size Selection :
Fixed step size (e.g., η k = 0.1 \eta_k = 0.1 η k = 0.1
Adaptive step size (e.g., η k = 1 k \eta_k = \frac{1}{\sqrt{k}} η k = k 1
Geometric Meaning : Each iteration moves linearly along the gradient direction by distance η k ∥ ∇ f ( x k ) ∥ \eta_k \|\nabla f(\mathbf{x}_k)\| η k ∥∇ f ( x k ) ∥
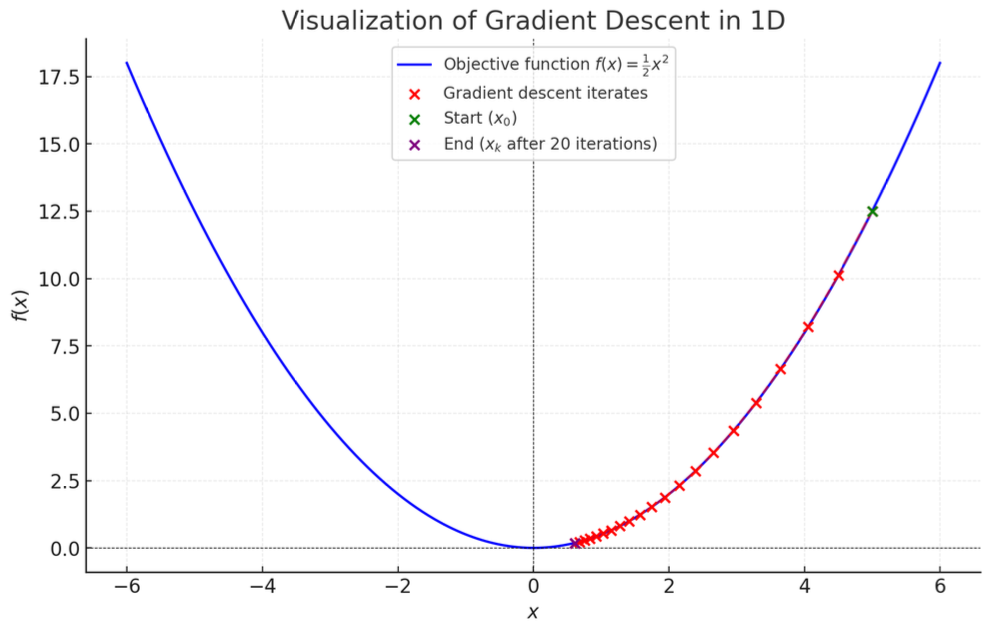
Gradient Descent Example: Quadratic Function Optimization
Consider the convex function f ( x ) = 1 2 x 2 f(x) = \frac{1}{2} x^2 f ( x ) = 2 1 x 2
Gradient Descent Update Rule
Iteration formula with fixed step size η \eta η
x t + 1 = x t − η ∇ f ( x t ) = x t − η x t = x t ( 1 − η ) x_{t+1} = x_t - \eta \nabla f(x_t) = x_t - \eta x_t = x_t (1 - \eta)
x t + 1 = x t − η ∇ f ( x t ) = x t − η x t = x t ( 1 − η )
After k k k
x k = x 0 ( 1 − η ) k x_k = x_0 (1 - \eta)^k
x k = x 0 ( 1 − η ) k
Derivation :
x k = x k − 1 ( 1 − η ) = x k − 2 ( 1 − η ) 2 = ⋯ = x 0 ( 1 − η ) k x_k = x_{k-1} (1 - \eta) = x_{k-2} (1 - \eta)^2 = \cdots = x_0 (1 - \eta)^k
x k = x k − 1 ( 1 − η ) = x k − 2 ( 1 − η ) 2 = ⋯ = x 0 ( 1 − η ) k
Convergence Analysis
When 0 < η < 1 0 < \eta < 1 0 < η < 1
lim k → ∞ x k = lim k → ∞ x 0 ( 1 − η ) k = 0 \lim_{k \to \infty} x_k = \lim_{k \to \infty} x_0 (1 - \eta)^k = 0
k → ∞ lim x k = k → ∞ lim x 0 ( 1 − η ) k = 0
Explanation :∣ 1 − η ∣ < 1 |1 - \eta| < 1 ∣1 − η ∣ < 1 ( 1 − η ) k (1 - \eta)^k ( 1 − η ) k x ∗ = 0 x^* = 0 x ∗ = 0
Convergence Behavior with Specific Parameters
Step Size : η = 0.1 \eta = 0.1 η = 0.1
Initial Point : x 0 = 5 x_0 = 5 x 0 = 5
Iteration Sequence :
x k = 5 × ( 0.9 ) k x_k = 5 \times (0.9)^k
x k = 5 × ( 0.9 ) k
Convergence Process :
k = 0 k=0 k = 0 x 0 = 5 x_0 = 5 x 0 = 5 k = 1 k=1 k = 1 x 1 = 5 × 0.9 = 4.5 x_1 = 5 \times 0.9 = 4.5 x 1 = 5 × 0.9 = 4.5 k = 10 k=10 k = 10 x 10 = 5 × ( 0.9 ) 10 ≈ 1.74 x_{10} = 5 \times (0.9)^{10} \approx 1.74 x 10 = 5 × ( 0.9 ) 10 ≈ 1.74 k = 50 k=50 k = 50 x 50 = 5 × ( 0.9 ) 50 ≈ 0.034 x_{50} = 5 \times (0.9)^{50} \approx 0.034 x 50 = 5 × ( 0.9 ) 50 ≈ 0.034
Conclusion :η = 0.1 \eta=0.1 η = 0.1 0 < η < 1 0<\eta<1 0 < η < 1 x ∗ = 0 x^*=0 x ∗ = 0
Vanilla Analysis of Gradient Descent
Goal: Bound the error f ( x t ) − f ( x ∗ ) f(\mathbf{x}_t) - f(\mathbf{x}^*) f ( x t ) − f ( x ∗ )
Define gradient g t : = ∇ f ( x t ) \mathbf{g}_t := \nabla f(\mathbf{x}_t) g t := ∇ f ( x t ) x t + 1 = x t − η g t \mathbf{x}_{t+1} = \mathbf{x}_t - \eta \mathbf{g}_t x t + 1 = x t − η g t
g t = x t − x t + 1 η \mathbf{g}_t = \frac{\mathbf{x}_t - \mathbf{x}_{t+1}}{\eta}
g t = η x t − x t + 1
Key Equality Derivation
Construct Inner Product Term :
g t ⊤ ( x t − x ∗ ) = 1 η ( x t − x t + 1 ) ⊤ ( x t − x ∗ ) \mathbf{g}_t^\top (\mathbf{x}_t - \mathbf{x}^*) = \frac{1}{\eta} (\mathbf{x}_t - \mathbf{x}_{t+1})^\top (\mathbf{x}_t - \mathbf{x}^*)
g t ⊤ ( x t − x ∗ ) = η 1 ( x t − x t + 1 ) ⊤ ( x t − x ∗ )
Apply Vector Identity (2 v ⊤ w = ∥ v ∥ 2 + ∥ w ∥ 2 − ∥ v − w ∥ 2 2\mathbf{v}^\top\mathbf{w} = \|\mathbf{v}\|^2 + \|\mathbf{w}\|^2 - \|\mathbf{v} - \mathbf{w}\|^2 2 v ⊤ w = ∥ v ∥ 2 + ∥ w ∥ 2 − ∥ v − w ∥ 2
g t ⊤ ( x t − x ∗ ) = 1 2 η ( ∥ x t − x t + 1 ∥ 2 + ∥ x t − x ∗ ∥ 2 − ∥ x t + 1 − x ∗ ∥ 2 ) = η 2 ∥ g t ∥ 2 + 1 2 η ( ∥ x t − x ∗ ∥ 2 − ∥ x t + 1 − x ∗ ∥ 2 ) \begin{aligned}
\mathbf{g}_t^\top (\mathbf{x}_t - \mathbf{x}^*)
&= \frac{1}{2\eta} \left( \|\mathbf{x}_t - \mathbf{x}_{t+1}\|^2 + \|\mathbf{x}_t - \mathbf{x}^*\|^2 - \|\mathbf{x}_{t+1} - \mathbf{x}^*\|^2 \right) \\
&= \frac{\eta}{2} \|\mathbf{g}_t\|^2 + \frac{1}{2\eta} \left( \|\mathbf{x}_t - \mathbf{x}^*\|^2 - \|\mathbf{x}_{t+1} - \mathbf{x}^*\|^2 \right)
\end{aligned}
g t ⊤ ( x t − x ∗ ) = 2 η 1 ( ∥ x t − x t + 1 ∥ 2 + ∥ x t − x ∗ ∥ 2 − ∥ x t + 1 − x ∗ ∥ 2 ) = 2 η ∥ g t ∥ 2 + 2 η 1 ( ∥ x t − x ∗ ∥ 2 − ∥ x t + 1 − x ∗ ∥ 2 )
Notes :
Term η 2 ∥ g t ∥ 2 \frac{\eta}{2} \|\mathbf{g}_t\|^2 2 η ∥ g t ∥ 2
Term 1 2 η ( ∥ x t − x ∗ ∥ 2 − ∥ x t + 1 − x ∗ ∥ 2 ) \frac{1}{2\eta} (\|\mathbf{x}_t - \mathbf{x}^*\|^2 - \|\mathbf{x}_{t+1} - \mathbf{x}^*\|^2) 2 η 1 ( ∥ x t − x ∗ ∥ 2 − ∥ x t + 1 − x ∗ ∥ 2 )
Sum over T T T :
∑ t = 0 T − 1 g t ⊤ ( x t − x ∗ ) = η 2 ∑ t = 0 T − 1 ∥ g t ∥ 2 + 1 2 η ( ∥ x 0 − x ∗ ∥ 2 − ∥ x T − x ∗ ∥ 2 ) \sum_{t=0}^{T-1} \mathbf{g}_t^\top (\mathbf{x}_t - \mathbf{x}^*) = \frac{\eta}{2} \sum_{t=0}^{T-1} \|\mathbf{g}_t\|^2 + \frac{1}{2\eta} \left( \|\mathbf{x}_0 - \mathbf{x}^*\|^2 - \|\mathbf{x}_T - \mathbf{x}^*\|^2 \right)
t = 0 ∑ T − 1 g t ⊤ ( x t − x ∗ ) = 2 η t = 0 ∑ T − 1 ∥ g t ∥ 2 + 2 η 1 ( ∥ x 0 − x ∗ ∥ 2 − ∥ x T − x ∗ ∥ 2 )
Combine with First-Order Convexity Condition
From convexity: f ( x ∗ ) ≥ f ( x t ) + g t ⊤ ( x ∗ − x t ) f(\mathbf{x}^*) \geq f(\mathbf{x}_t) + \mathbf{g}_t^\top (\mathbf{x}^* - \mathbf{x}_t) f ( x ∗ ) ≥ f ( x t ) + g t ⊤ ( x ∗ − x t )
f ( x t ) − f ( x ∗ ) ≤ g t ⊤ ( x t − x ∗ ) f(\mathbf{x}_t) - f(\mathbf{x}^*) \leq \mathbf{g}_t^\top (\mathbf{x}_t - \mathbf{x}^*)
f ( x t ) − f ( x ∗ ) ≤ g t ⊤ ( x t − x ∗ )
Substitute into summation for cumulative error bound:
∑ t = 0 T − 1 [ f ( x t ) − f ( x ∗ ) ] ≤ η 2 ∑ t = 0 T − 1 ∥ g t ∥ 2 + 1 2 η ( ∥ x 0 − x ∗ ∥ 2 − ∥ x T − x ∗ ∥ 2 ) \sum_{t=0}^{T-1} \left[ f(\mathbf{x}_t) - f(\mathbf{x}^*) \right] \leq \frac{\eta}{2} \sum_{t=0}^{T-1} \|\mathbf{g}_t\|^2 + \frac{1}{2\eta} \left( \|\mathbf{x}_0 - \mathbf{x}^*\|^2 - \|\mathbf{x}_T - \mathbf{x}^*\|^2 \right)
t = 0 ∑ T − 1 [ f ( x t ) − f ( x ∗ ) ] ≤ 2 η t = 0 ∑ T − 1 ∥ g t ∥ 2 + 2 η 1 ( ∥ x 0 − x ∗ ∥ 2 − ∥ x T − x ∗ ∥ 2 )
Key Conclusions :
Cumulative error is controlled by gradient norm sum ∑ ∥ g t ∥ 2 \sum \|\mathbf{g}_t\|^2 ∑ ∥ g t ∥ 2 ∥ x 0 − x ∗ ∥ 2 \|\mathbf{x}_0 - \mathbf{x}^*\|^2 ∥ x 0 − x ∗ ∥ 2
Step Size η \eta η :
Too large: Gradient term η 2 ∑ ∥ g t ∥ 2 \frac{\eta}{2} \sum \|\mathbf{g}_t\|^2 2 η ∑ ∥ g t ∥ 2
Too small: Distance term 1 2 η ∥ x 0 − x ∗ ∥ 2 \frac{1}{2\eta} \|\mathbf{x}_0 - \mathbf{x}^*\|^2 2 η 1 ∥ x 0 − x ∗ ∥ 2
Convergence Analysis for Lipschitz Convex Functions
Assume all gradients of f have bounded norm.
Equivalent to f f f
Excludes many interesting functions (e.g., f ( x ) = x 2 f(x) = x^2 f ( x ) = x 2
Equivalence Proof
Let f : R d → R f: \mathbb{R}^d \to \mathbb{R} f : R d → R
Bounded Gradient : ∃ M > 0 \exists M > 0 ∃ M > 0 ∥ ∇ f ( x ) ∥ ≤ M , ∀ x \|\nabla f(x)\| \leq M, \ \forall x ∥∇ f ( x ) ∥ ≤ M , ∀ x
Lipschitz Continuity : ∃ L > 0 \exists L > 0 ∃ L > 0 ∥ f ( y ) − f ( x ) ∥ ≤ L ∥ y − x ∥ , ∀ x , y \|f(y) - f(x)\| \leq L \|y - x\|, \ \forall x, y ∥ f ( y ) − f ( x ) ∥ ≤ L ∥ y − x ∥ , ∀ x , y
Proof Outline (⇒) Bounded Gradient ⇒ Lipschitz Continuity Assume ∥ ∇ f ( x ) ∥ ≤ M \|\nabla f(x)\| \leq M ∥∇ f ( x ) ∥ ≤ M
f ( y ) − f ( x ) = ∫ 0 1 ∇ f ( x + t ( y − x ) ) ⊤ ( y − x ) d t f(y) - f(x) = \int_0^1 \nabla f(x + t(y-x))^\top (y-x) \, dt
f ( y ) − f ( x ) = ∫ 0 1 ∇ f ( x + t ( y − x ) ) ⊤ ( y − x ) d t
Take norms and apply Cauchy-Schwarz:
∥ f ( y ) − f ( x ) ∥ ≤ ∫ 0 1 ∥ ∇ f ( x + t ( y − x ) ) ∥ ⋅ ∥ y − x ∥ d t \|f(y) - f(x)\| \leq \int_0^1 \|\nabla f(x + t(y-x))\| \cdot \|y - x\| \, dt
∥ f ( y ) − f ( x ) ∥ ≤ ∫ 0 1 ∥∇ f ( x + t ( y − x )) ∥ ⋅ ∥ y − x ∥ d t
Substitute bounded gradient condition:
∥ f ( y ) − f ( x ) ∥ ≤ ∫ 0 1 M ∥ y − x ∥ d t = M ∥ y − x ∥ \|f(y) - f(x)\| \leq \int_0^1 M \|y - x\| \, dt = M \|y - x\|
∥ f ( y ) − f ( x ) ∥ ≤ ∫ 0 1 M ∥ y − x ∥ d t = M ∥ y − x ∥
Thus f f f M M M
Explanation : Bounded gradient norm controls function value change rate.
(⇐) Lipschitz Continuity ⇒ Bounded Gradient Assume ∥ f ( y ) − f ( x ) ∥ ≤ L ∥ y − x ∥ \|f(y) - f(x)\| \leq L \|y - x\| ∥ f ( y ) − f ( x ) ∥ ≤ L ∥ y − x ∥ f f f ∥ ∇ f ( x ) ∥ ≤ L \|\nabla f(x)\| \leq L ∥∇ f ( x ) ∥ ≤ L
If ∇ f ( x ) = 0 \nabla f(x) = 0 ∇ f ( x ) = 0 : Trivial.
Otherwise : Set y = x + ∇ f ( x ) y = x + \nabla f(x) y = x + ∇ f ( x )
f ( y ) ≥ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) f(y) \geq f(x) + \nabla f(x)^\top (y - x)
f ( y ) ≥ f ( x ) + ∇ f ( x ) ⊤ ( y − x )
Substitute y − x = ∇ f ( x ) y - x = \nabla f(x) y − x = ∇ f ( x )
f ( y ) − f ( x ) ≥ ∇ f ( x ) ⊤ ∇ f ( x ) = ∥ ∇ f ( x ) ∥ 2 ( ∗ ) f(y) - f(x) \geq \nabla f(x)^\top \nabla f(x) = \|\nabla f(x)\|^2 \quad (*)
f ( y ) − f ( x ) ≥ ∇ f ( x ) ⊤ ∇ f ( x ) = ∥∇ f ( x ) ∥ 2 ( ∗ )
By Lipschitz continuity:
f ( y ) − f ( x ) ≤ L ∥ y − x ∥ = L ∥ ∇ f ( x ) ∥ ( ∗ ∗ ) f(y) - f(x) \leq L \|y - x\| = L \|\nabla f(x)\| \quad (**)
f ( y ) − f ( x ) ≤ L ∥ y − x ∥ = L ∥∇ f ( x ) ∥ ( ∗ ∗ )
Combine ( ∗ ) (*) ( ∗ ) ( ∗ ∗ ) (**) ( ∗ ∗ )
∥ ∇ f ( x ) ∥ 2 ≤ L ∥ ∇ f ( x ) ∥ \|\nabla f(x)\|^2 \leq L \|\nabla f(x)\|
∥∇ f ( x ) ∥ 2 ≤ L ∥∇ f ( x ) ∥
Thus ∥ ∇ f ( x ) ∥ ≤ L \|\nabla f(x)\| \leq L ∥∇ f ( x ) ∥ ≤ L
Explanation : Lipschitz continuity restricts linear growth of function values, forcing bounded gradient norm.
Fundamental Theorem Application :
f ( y ) − f ( x ) = ∫ 0 1 ∇ f ( x + t ( y − x ) ) ⊤ ( y − x ) d t f(y) - f(x) = \int_0^1 \nabla f(x + t(y-x))^\top (y-x) \, dt
f ( y ) − f ( x ) = ∫ 0 1 ∇ f ( x + t ( y − x ) ) ⊤ ( y − x ) d t
Meaning : Expresses function difference as path integral of gradient.
Cauchy-Schwarz Inequality :
∣ ∇ f ( z ) ⊤ ( y − x ) ∣ ≤ ∥ ∇ f ( z ) ∥ ⋅ ∥ y − x ∥ \left| \nabla f(z)^\top (y-x) \right| \leq \|\nabla f(z)\| \cdot \|y - x\|
∇ f ( z ) ⊤ ( y − x ) ≤ ∥∇ f ( z ) ∥ ⋅ ∥ y − x ∥
Role : Converts inner product to norm product for integral bounding.
First-Order Convexity Condition :
f ( y ) ≥ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) f(y) \geq f(x) + \nabla f(x)^\top (y - x)
f ( y ) ≥ f ( x ) + ∇ f ( x ) ⊤ ( y − x )
Role : Establishes one-way relationship between gradient and function value change.
Appendix: P47 Example f ( x ) = ∣ x ∣ f(x) = |x| f ( x ) = ∣ x ∣
At x > 0 x > 0 x > 0 g k = 1 g_k = 1 g k = 1 x ∗ = 0 x^* = 0 x ∗ = 0
At x = 0 x = 0 x = 0 g k ∈ [ − 1 , 1 ] g_k \in [-1, 1] g k ∈ [ − 1 , 1 ]
Theorem Setup Let f : R d → R f: \mathbb{R}^d \to \mathbb{R} f : R d → R
∥ x 0 − x ∗ ∥ ≤ R \|\mathbf{x}_0 - \mathbf{x}^*\| \leq R ∥ x 0 − x ∗ ∥ ≤ R
∥ ∇ f ( x ) ∥ ≤ B , ∀ x \|\nabla f(\mathbf{x})\| \leq B,\ \forall \mathbf{x} ∥∇ f ( x ) ∥ ≤ B , ∀ x B B B f f f
Convergence Proof
Base Inequality (from Vanilla Analysis):
∑ t = 0 T − 1 [ f ( x t ) − f ( x ∗ ) ] ≤ η 2 ∑ t = 0 T − 1 ∥ g t ∥ 2 + 1 2 η ∥ x 0 − x ∗ ∥ 2 \sum_{t=0}^{T-1} [f(\mathbf{x}_t) - f(\mathbf{x}^*)] \leq \frac{\eta}{2} \sum_{t=0}^{T-1} \|\mathbf{g}_t\|^2 + \frac{1}{2\eta} \|\mathbf{x}_0 - \mathbf{x}^*\|^2
t = 0 ∑ T − 1 [ f ( x t ) − f ( x ∗ )] ≤ 2 η t = 0 ∑ T − 1 ∥ g t ∥ 2 + 2 η 1 ∥ x 0 − x ∗ ∥ 2
Substitute Bounded Conditions :
∑ t = 0 T − 1 [ f ( x t ) − f ( x ∗ ) ] ≤ η 2 B 2 T + R 2 2 η \sum_{t=0}^{T-1} [f(\mathbf{x}_t) - f(\mathbf{x}^*)] \leq \frac{\eta}{2} B^2 T + \frac{R^2}{2\eta}
t = 0 ∑ T − 1 [ f ( x t ) − f ( x ∗ )] ≤ 2 η B 2 T + 2 η R 2
Optimize Step Size η \eta η :
h ( η ) = η B 2 T 2 + R 2 2 η h(\eta) = \frac{\eta B^2 T}{2} + \frac{R^2}{2\eta}
h ( η ) = 2 η B 2 T + 2 η R 2
Optimal step size via derivative:h ′ ( η ) = B 2 T 2 − R 2 2 η 2 = 0 ⇒ η ∗ = R B T h'(\eta) = \frac{B^2 T}{2} - \frac{R^2}{2\eta^2} = 0 \ \Rightarrow \ \eta^* = \frac{R}{B\sqrt{T}}
h ′ ( η ) = 2 B 2 T − 2 η 2 R 2 = 0 ⇒ η ∗ = B T R
Substitute for minimal bound:h ( η ∗ ) = R B T ⋅ B 2 T 2 + R 2 2 ⋅ R B T = R B T h(\eta^*) = \frac{R}{B\sqrt{T}} \cdot \frac{B^2 T}{2} + \frac{R^2}{2 \cdot \frac{R}{B\sqrt{T}}} = RB\sqrt{T}
h ( η ∗ ) = B T R ⋅ 2 B 2 T + 2 ⋅ B T R R 2 = RB T
Average Error Bound
1 T ∑ t = 0 T − 1 [ f ( x t ) − f ( x ∗ ) ] ≤ R B T \frac{1}{T} \sum_{t=0}^{T-1} [f(\mathbf{x}_t) - f(\mathbf{x}^*)] \leq \frac{RB}{\sqrt{T}}
T 1 t = 0 ∑ T − 1 [ f ( x t ) − f ( x ∗ )] ≤ T RB
Convergence Rate and Iteration Count
Note : Lipschitz condition excludes functions with unbounded gradients (e.g., f ( x ) = x 2 f(x)=x^2 f ( x ) = x 2
Practical Advice (Unknown R R R B B B
Fixed Small Step Size : Start with η = 0.01 \eta = 0.01 η = 0.01
Dynamic Adjustment :
Oscillation/divergence → decrease η \eta η
Or use decaying step size η t = η 0 t + 1 \eta_t = \frac{\eta_0}{\sqrt{t+1}} η t = t + 1 η 0
Adaptive Methods : Use adaptive optimizers like Adam
Smooth Functions
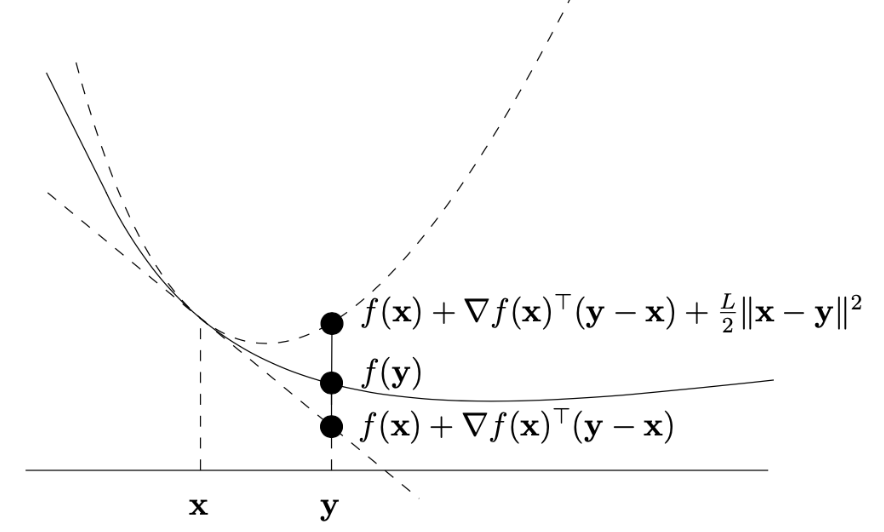
Definition
A differentiable function f : dom ( f ) → R f : \text{dom}(f) \to \mathbb{R} f : dom ( f ) → R smooth with parameter L > 0 L > 0 L > 0 X ⊆ dom ( f ) X \subseteq \text{dom}(f) X ⊆ dom ( f ) x , y ∈ X x, y \in X x , y ∈ X
f ( y ) ≤ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) + L 2 ∥ x − y ∥ 2 f(y) \leq f(x) + \nabla f(x)^\top (y - x) + \frac{L}{2} \|x - y\|^2
f ( y ) ≤ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) + 2 L ∥ x − y ∥ 2
Intuition :
The function “does not bend too much,” its growth is bounded by a quadratic function (like a paraboloid).
L L L L L L
Geometric Interpretation
Smoothness implies: Near any point x x x f f f
Example :f ( x ) = x 2 f(x) = x^2 f ( x ) = x 2
Operations Preserving Smoothness
The following operations preserve smoothness under specified conditions:
Lemma 1 f 1 , … , f m f_1, \dots, f_m f 1 , … , f m L 1 , … , L m L_1, \dots, L_m L 1 , … , L m λ 1 , … , λ m ∈ R + \lambda_1, \dots, \lambda_m \in \mathbb{R}^+ λ 1 , … , λ m ∈ R + f : = ∑ i = 1 m λ i f i f := \sum_{i=1}^m \lambda_i f_i f := ∑ i = 1 m λ i f i ∑ i = 1 m λ i L i \sum_{i=1}^m \lambda_i L_i ∑ i = 1 m λ i L i f f f L L L g : R m → R d g: \mathbb{R}^m \to \mathbb{R}^d g : R m → R d g ( x ) = A x + b g(x) = Ax + b g ( x ) = A x + b A ∈ R d × m A \in \mathbb{R}^{d \times m} A ∈ R d × m b ∈ R d b \in \mathbb{R}^d b ∈ R d f ∘ g f \circ g f ∘ g x ↦ f ( A x + b ) x \mapsto f(Ax + b) x ↦ f ( A x + b ) L ∥ A ∥ 2 L \|A\|_2 L ∥ A ∥ 2
Here ∥ A ∥ 2 \|A\|_2 ∥ A ∥ 2 spectral norm of A A A
Convex vs. Smooth Functions: Properties and Optimization
Basic Concept Comparison
Property
Mathematical Definition
Geometric Meaning
Optimization Implication
Convexity f ( λ x + ( 1 − λ ) y ) ≤ λ f ( x ) + ( 1 − λ ) f ( y ) f(\lambda x + (1-\lambda)y) \leq \lambda f(x) + (1-\lambda)f(y) f ( λ x + ( 1 − λ ) y ) ≤ λ f ( x ) + ( 1 − λ ) f ( y ) Graph below chords
Guarantees global optimality
Lipschitz Continuity ∣ ∇ f ( x ) ∣ ≤ B |\nabla f(x)| \leq B ∣∇ f ( x ) ∣ ≤ B Bounded gradient, controlled change rate
Controls gradient descent stability
Smoothness ∣ ∇ f ( x ) − ∇ f ( y ) ∣ ≤ L ∣ x − y ∣ |\nabla f(x) - \nabla f(y)| \leq L|x-y| ∣∇ f ( x ) − ∇ f ( y ) ∣ ≤ L ∣ x − y ∣ Gentle gradient changes, bounded curvature
Enables faster convergence rates
Key Equivalence
Lemma 2: Equivalent Characterizations of Smoothness
For convex differentiable f : R d → R f: \mathbb{R}^d \to \mathbb{R} f : R d → R
f f f L L L f ( y ) ≤ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) + L 2 ∥ x − y ∥ 2 f(y) \leq f(x) + \nabla f(x)^\top(y-x) + \frac{L}{2}\|x-y\|^2 f ( y ) ≤ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) + 2 L ∥ x − y ∥ 2
Gradient is L L L ∥ ∇ f ( x ) − ∇ f ( y ) ∥ ≤ L ∥ x − y ∥ \|\nabla f(x) - \nabla f(y)\| \leq L\|x-y\| ∥∇ f ( x ) − ∇ f ( y ) ∥ ≤ L ∥ x − y ∥
Significance : Establishes equivalence between function smoothness and gradient Lipschitz continuity.
Gradient Descent Analysis for Smooth Functions
Lemma 3: Sufficient Decrease
For L L L η = 1 L \eta = \frac{1}{L} η = L 1
f ( x t + 1 ) ≤ f ( x t ) − 1 2 L ∥ ∇ f ( x t ) ∥ 2 f(x_{t+1}) \leq f(x_t) - \frac{1}{2L} \|\nabla f(x_t)\|^2
f ( x t + 1 ) ≤ f ( x t ) − 2 L 1 ∥∇ f ( x t ) ∥ 2
Proof :
f ( x t + 1 ) ≤ f ( x t ) + ∇ f ( x t ) ⊤ ( x t + 1 − x t ) + L 2 ∥ x t + 1 − x t ∥ 2 = f ( x t ) − 1 L ∥ ∇ f ( x t ) ∥ 2 + 1 2 L ∥ ∇ f ( x t ) ∥ 2 = f ( x t ) − 1 2 L ∥ ∇ f ( x t ) ∥ 2 \begin{aligned}
f(x_{t+1}) &\leq f(x_t) + \nabla f(x_t)^\top(x_{t+1}-x_t) + \frac{L}{2}\|x_{t+1}-x_t\|^2 \\
&= f(x_t) - \frac{1}{L} \|\nabla f(x_t)\|^2 + \frac{1}{2L} \|\nabla f(x_t)\|^2 \\
&= f(x_t) - \frac{1}{2L} \|\nabla f(x_t)\|^2
\end{aligned}
f ( x t + 1 ) ≤ f ( x t ) + ∇ f ( x t ) ⊤ ( x t + 1 − x t ) + 2 L ∥ x t + 1 − x t ∥ 2 = f ( x t ) − L 1 ∥∇ f ( x t ) ∥ 2 + 2 L 1 ∥∇ f ( x t ) ∥ 2 = f ( x t ) − 2 L 1 ∥∇ f ( x t ) ∥ 2
Meaning : Each iteration guarantees function value decrease, controlled by gradient norm.
Theorem 2: Convergence Rate
For L L L f f f η = 1 L \eta = \frac{1}{L} η = L 1
f ( x T ) − f ( x ∗ ) ≤ L ∥ x 0 − x ∗ ∥ 2 2 T f(x_T) - f(x^*) \leq \frac{L \|x_0 - x^*\|^2}{2T}
f ( x T ) − f ( x ∗ ) ≤ 2 T L ∥ x 0 − x ∗ ∥ 2
Proof Sketch :
Use base analysis inequality
Apply sufficient decrease lemma to bound gradient term
Obtain final bound via telescoping sum
Practical Applications and Comparisons
Convergence Rate Comparison
Function Type
Convergence Rate
Iteration Complexity (ε \varepsilon ε
Lipschitz Convex
O ( 1 / T ) O(1/\sqrt{T}) O ( 1/ T ) O ( 1 / ε 2 ) O(1/\varepsilon^2) O ( 1/ ε 2 )
Smooth Convex
O ( 1 / T ) O(1/T) O ( 1/ T ) O ( 1 / ε ) O(1/\varepsilon) O ( 1/ ε )
Advantage : Smoothness improves convergence from sublinear to linear, significantly boosting efficiency.
Practical Advice: Unknown L L L
Initial Guess : Set L = 2 ε R 2 L = \frac{2\varepsilon}{R^2} L = R 2 2 ε
Verification : Check f ( x t + 1 ) ≤ f ( x t ) − 1 2 L ∥ ∇ f ( x t ) ∥ 2 f(x_{t+1}) \leq f(x_t) - \frac{1}{2L} \|\nabla f(x_t)\|^2 f ( x t + 1 ) ≤ f ( x t ) − 2 L 1 ∥∇ f ( x t ) ∥ 2
Doubling Strategy : If condition fails, double L L L
Total Complexity : At most O ( 4 R 2 L ε ) O\left(\frac{4R^2L}{\varepsilon}\right) O ( ε 4 R 2 L ) ε \varepsilon ε
Practical Impact : Adaptive adjustment enables efficient optimization even without knowing L L L
Subgradient Method
Subgradient Definition
For convex f : R d → R f: \mathbb{R}^d \to \mathbb{R} f : R d → R x \mathbf{x} x g ∈ R d \mathbf{g} \in \mathbb{R}^d g ∈ R d
f ( y ) ≥ f ( x ) + g ⊤ ( y − x ) , ∀ y f(\mathbf{y}) \geq f(\mathbf{x}) + \mathbf{g}^\top (\mathbf{y} - \mathbf{x}), \quad \forall \mathbf{y}
f ( y ) ≥ f ( x ) + g ⊤ ( y − x ) , ∀ y
Key Properties :
Always exists at points in the domain
If f f f x \mathbf{x} x ∇ f ( x ) \nabla f(\mathbf{x}) ∇ f ( x )
Subgradient Calculation Examples
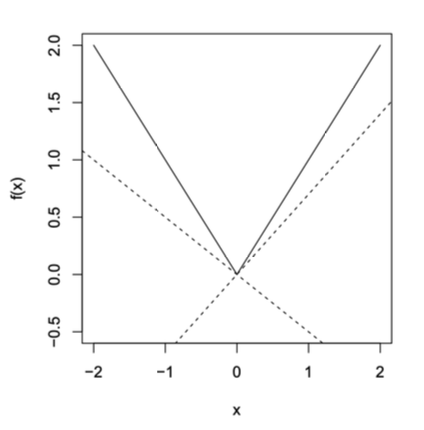
Example 1: Absolute Value f ( x ) = ∣ x ∣ f(x) = |x| f ( x ) = ∣ x ∣
For x ≠ 0 x \neq 0 x = 0 g = sign ( x ) g = \text{sign}(x) g = sign ( x )
For x = 0 x = 0 x = 0 g ∈ [ − 1 , 1 ] g \in [-1, 1] g ∈ [ − 1 , 1 ]
Example 2: L2 Norm f ( x ) = ∥ x ∥ 2 f(\mathbf{x}) = \|\mathbf{x}\|_2 f ( x ) = ∥ x ∥ 2
For x ≠ 0 \mathbf{x} \neq \mathbf{0} x = 0 g = x ∥ x ∥ 2 \mathbf{g} = \frac{\mathbf{x}}{\|\mathbf{x}\|_2} g = ∥ x ∥ 2 x
For x = 0 \mathbf{x} = \mathbf{0} x = 0 g \mathbf{g} g { z : ∥ z ∥ 2 ≤ 1 } \{\mathbf{z} : \|\mathbf{z}\|_2 \leq 1\} { z : ∥ z ∥ 2 ≤ 1 }
Example 3: L1 Norm f ( x ) = ∥ x ∥ 1 = ∑ i = 1 d ∣ x i ∣ f(\mathbf{x}) = \|\mathbf{x}\|_1 = \sum_{i=1}^d |x_i| f ( x ) = ∥ x ∥ 1 = ∑ i = 1 d ∣ x i ∣
For x i ≠ 0 x_i \neq 0 x i = 0 g i = sign ( x i ) g_i = \text{sign}(x_i) g i = sign ( x i )
For x i = 0 x_i = 0 x i = 0 g i ∈ [ − 1 , 1 ] g_i \in [-1, 1] g i ∈ [ − 1 , 1 ]
Example 4: Set Indicator Function
For convex set X ⊂ R d X \subset \mathbb{R}^d X ⊂ R d
1 X ( x ) = { 0 if x ∈ X + ∞ if x ∉ X 1_X(\mathbf{x}) =
\begin{cases}
0 & \text{if } \mathbf{x} \in X \\
+\infty & \text{if } \mathbf{x} \notin X
\end{cases}
1 X ( x ) = { 0 + ∞ if x ∈ X if x ∈ / X
Normal Cone
Definition : For convex set X ⊆ R d X \subseteq \mathbb{R}^d X ⊆ R d x ∈ X \mathbf{x} \in X x ∈ X
N X ( x ) = { g ∈ R d ∣ g ⊤ x ≥ g ⊤ y , ∀ y ∈ X } \mathcal{N}_X(\mathbf{x}) = \{ \mathbf{g} \in \mathbb{R}^d \mid \mathbf{g}^\top \mathbf{x} \geq \mathbf{g}^\top \mathbf{y},\ \forall \mathbf{y} \in X \}
N X ( x ) = { g ∈ R d ∣ g ⊤ x ≥ g ⊤ y , ∀ y ∈ X }
Geometric Interpretation : Contains outward-pointing vectors “supporting” X X X x \mathbf{x} x x \mathbf{x} x
Subdifferential
Definition : The subdifferential of convex f : R d → R f: \mathbb{R}^d \to \mathbb{R} f : R d → R x \mathbf{x} x
∂ f ( x ) = { g ∈ R d ∣ f ( y ) ≥ f ( x ) + g ⊤ ( y − x ) , ∀ y ∈ R d } \partial f(\mathbf{x}) = \{ \mathbf{g} \in \mathbb{R}^d \mid f(\mathbf{y}) \geq f(\mathbf{x}) + \mathbf{g}^\top (\mathbf{y} - \mathbf{x}),\ \forall \mathbf{y} \in \mathbb{R}^d \}
∂ f ( x ) = { g ∈ R d ∣ f ( y ) ≥ f ( x ) + g ⊤ ( y − x ) , ∀ y ∈ R d }
Properties :
∂ f ( x ) \partial f(\mathbf{x}) ∂ f ( x )
If f f f x \mathbf{x} x ∂ f ( x ) = { ∇ f ( x ) } \partial f(\mathbf{x}) = \{ \nabla f(\mathbf{x}) \} ∂ f ( x ) = { ∇ f ( x )}
If ∂ f ( x ) \partial f(\mathbf{x}) ∂ f ( x ) f f f x \mathbf{x} x ∇ f ( x ) = g \nabla f(\mathbf{x}) = \mathbf{g} ∇ f ( x ) = g
Optimality Conditions
Unconstrained Optimization
For convex f : R d → R f: \mathbb{R}^d \to \mathbb{R} f : R d → R
x ∗ minimizes f ⟺ 0 ∈ ∂ f ( x ∗ ) \mathbf{x}^* \text{ minimizes } f \iff 0 \in \partial f(\mathbf{x}^*)
x ∗ minimizes f ⟺ 0 ∈ ∂ f ( x ∗ )
Interpretation : x ∗ \mathbf{x}^* x ∗
Constrained Optimization
Consider:
min x f ( x ) s.t. x ∈ X \min_{\mathbf{x}} f(\mathbf{x}) \quad \text{s.t.} \quad \mathbf{x} \in X
x min f ( x ) s.t. x ∈ X
Reformulation : Introduce indicator function 1 X ( x ) 1_X(\mathbf{x}) 1 X ( x )
min x { f ( x ) + 1 X ( x ) } \min_{\mathbf{x}} \left\{ f(\mathbf{x}) + 1_X(\mathbf{x}) \right\}
x min { f ( x ) + 1 X ( x ) }
Optimality Condition : x ∗ ∈ X \mathbf{x}^* \in X x ∗ ∈ X
0 ∈ ∂ ( f ( x ∗ ) + 1 X ( x ∗ ) ) = ∇ f ( x ∗ ) + N X ( x ∗ ) 0 \in \partial \left( f(\mathbf{x}^*) + 1_X(\mathbf{x}^*) \right) = \nabla f(\mathbf{x}^*) + \mathcal{N}_X(\mathbf{x}^*)
0 ∈ ∂ ( f ( x ∗ ) + 1 X ( x ∗ ) ) = ∇ f ( x ∗ ) + N X ( x ∗ )
Equivalently:
− ∇ f ( x ∗ ) ∈ N X ( x ∗ ) - \nabla f(\mathbf{x}^*) \in \mathcal{N}_X(\mathbf{x}^*)
− ∇ f ( x ∗ ) ∈ N X ( x ∗ )
By normal cone definition, this means:
∇ f ( x ∗ ) ⊤ ( y − x ∗ ) ≥ 0 , ∀ y ∈ X \nabla f(\mathbf{x}^*)^\top (\mathbf{y} - \mathbf{x}^*) \geq 0, \quad \forall \mathbf{y} \in X
∇ f ( x ∗ ) ⊤ ( y − x ∗ ) ≥ 0 , ∀ y ∈ X
Geometric Interpretation : At optimum x ∗ \mathbf{x}^* x ∗
Subgradient Method
Basic Concepts
For a convex function f : R d → R f : \mathbb{R}^d \to \mathbb{R} f : R d → R subgradient instead of the gradient:
x k + 1 = x k − η k + 1 g k x_{k+1} = x_k - \eta_{k+1} g_k
x k + 1 = x k − η k + 1 g k
x k x_k x k
g k ∈ ∇ f ( x k ) g_k \in \nabla f(x_k) g k ∈ ∇ f ( x k ) f f f x k x_k x k
η k > 0 \eta_k > 0 η k > 0
x k + 1 x_{k+1} x k + 1
⚠️ Note: The subgradient method is not necessarily a descent method. For example, when f ( x ) = ∣ x ∣ f(x) = |x| f ( x ) = ∣ x ∣
Convergence Theorem
Theorem 3 : Assume f f f L-Lipschitz (i.e., ∣ f ( x ) − f ( y ) ∣ ≤ L ∥ x − y ∥ |f(x) - f(y)| \leq L \|x - y\| ∣ f ( x ) − f ( y ) ∣ ≤ L ∥ x − y ∥
Fixed step size η k = η \eta_k = \eta η k = η k k k
lim k → ∞ f ( x best ( k ) ) ≤ f ∗ + L 2 η 2 \lim_{k \to \infty} f(x_{\text{best}}^{(k)}) \leq f^* + \frac{L^2 \eta}{2}
k → ∞ lim f ( x best ( k ) ) ≤ f ∗ + 2 L 2 η
Diminishing step size (satisfying ∑ k = 1 ∞ η k 2 < ∞ \sum_{k=1}^\infty \eta_k^2 < \infty ∑ k = 1 ∞ η k 2 < ∞ ∑ k = 1 ∞ η k = ∞ \sum_{k=1}^\infty \eta_k = \infty ∑ k = 1 ∞ η k = ∞
lim k → ∞ f ( x best ( k ) ) ≤ f ∗ \lim_{k \to \infty} f(x_{\text{best}}^{(k)}) \leq f^*
k → ∞ lim f ( x best ( k ) ) ≤ f ∗
Where:
f ( x best ( k ) ) = min i = 0 , … , k f ( x i ) f(x_{\text{best}}^{(k)}) = \min_{i=0,\dots,k} f(x_i) f ( x best ( k ) ) = min i = 0 , … , k f ( x i ) k k k f ∗ = f ( x ∗ ) f^* = f(x^*) f ∗ = f ( x ∗ )
Key Steps of the Proof
Based on the definition of the subgradient, we can derive the basic inequality:
∥ x k − x ∗ ∥ 2 ≤ ∥ x k − 1 − x ∗ ∥ 2 − 2 η k ( f ( x k − 1 ) − f ∗ ) + η k 2 ∥ g k − 1 ∥ 2 \|x_k - x^*\|^2 \leq \|x_{k-1} - x^*\|^2 - 2\eta_k (f(x_{k-1}) - f^*) + \eta_k^2 \|g_{k-1}\|^2
∥ x k − x ∗ ∥ 2 ≤ ∥ x k − 1 − x ∗ ∥ 2 − 2 η k ( f ( x k − 1 ) − f ∗ ) + η k 2 ∥ g k − 1 ∥ 2
Iterating this inequality and rearranging (let R = ∥ x 0 − x ∗ ∥ R = \|x_0 - x^*\| R = ∥ x 0 − x ∗ ∥
0 ≤ R 2 − 2 ∑ i = 1 k η i ( f ( x i − 1 ) − f ∗ ) + L 2 ∑ i = 1 k η i 2 0 \leq R^2 - 2 \sum_{i=1}^k \eta_i (f(x_{i-1}) - f^*) + L^2 \sum_{i=1}^k \eta_i^2
0 ≤ R 2 − 2 i = 1 ∑ k η i ( f ( x i − 1 ) − f ∗ ) + L 2 i = 1 ∑ k η i 2
After introducing f ( x best ( k ) ) f(x_{\text{best}}^{(k)}) f ( x best ( k ) ) basic inequality :
f ( x best ( k ) ) − f ∗ ≤ R 2 + L 2 ∑ i = 1 k η i 2 2 ∑ i = 1 k η i f(x_{\text{best}}^{(k)}) - f^* \leq \frac{R^2 + L^2 \sum_{i=1}^k \eta_i^2}{2 \sum_{i=1}^k \eta_i}
f ( x best ( k ) ) − f ∗ ≤ 2 ∑ i = 1 k η i R 2 + L 2 ∑ i = 1 k η i 2
The convergence results for different step size strategies can be derived from this.
Convergence Rate with Fixed Step Size
If the step size is fixed as η \eta η
f ( x best ( k ) ) − f ∗ ≤ R 2 2 k η + L 2 η 2 f(x_{\text{best}}^{(k)}) - f^* \leq \frac{R^2}{2k\eta} + \frac{L^2 \eta}{2}
f ( x best ( k ) ) − f ∗ ≤ 2 k η R 2 + 2 L 2 η
To achieve accuracy f ( x best ( k ) ) − f ∗ ≤ ε f(x_{\text{best}}^{(k)}) - f^* \leq \varepsilon f ( x best ( k ) ) − f ∗ ≤ ε ≤ ε / 2 \leq \varepsilon/2 ≤ ε /2
Therefore, the convergence rate of the subgradient method is O ( 1 ε 2 ) O\left(\frac{1}{\varepsilon^2}\right) O ( ε 2 1 )
📉 Comparison: The convergence rate of gradient descent for smooth convex functions is O ( 1 ε ) O\left(\frac{1}{\varepsilon}\right) O ( ε 1 )
Summary of Algorithm Convergence
Function Properties
Algorithm
Convergence Bound
Number of Iterations
Convex, L-Lipschitz
Subgradient
f ( x best ( T ) ) − f ∗ ≤ L R T f(x_{\text{best}}^{(T)}) - f^* \leq \frac{LR}{\sqrt{T}} f ( x best ( T ) ) − f ∗ ≤ T L R O ( R 2 L 2 ε 2 ) O\left(\frac{R^2 L^2}{\varepsilon^2}\right) O ( ε 2 R 2 L 2 )
Convex, L-Smooth
Gradient Descent
f ( x best ( T ) ) − f ∗ ≤ R 2 L 2 T f(x_{\text{best}}^{(T)}) - f^* \leq \frac{R^2 L}{2T} f ( x best ( T ) ) − f ∗ ≤ 2 T R 2 L O ( R 2 L ε ) O\left(\frac{R^2 L}{\varepsilon}\right) O ( ε R 2 L )
Convex, L-Lipschitz
Gradient Descent
f ( x best ( T ) ) − f ∗ ≤ R L T f(x_{\text{best}}^{(T)}) - f^* \leq \frac{RL}{\sqrt{T}} f ( x best ( T ) ) − f ∗ ≤ T R L O ( R 2 L 2 ε 2 ) O\left(\frac{R^2 L^2}{\varepsilon^2}\right) O ( ε 2 R 2 L 2 )
Where:
T T T R = ∥ x 0 − x ∗ ∥ R = \|x_0 - x^*\| R = ∥ x 0 − x ∗ ∥ x best ( T ) = arg min i = 0 , 1 , … , T f ( x i ) x_{\text{best}}^{(T)} = \arg\min_{i=0,1,\dots,T} f(x_i) x best ( T ) = arg min i = 0 , 1 , … , T f ( x i ) T T T
Summary
Expand
Convex Function Definition
f : R d → R f: \mathbb{R}^d \to \mathbb{R} f : R d → R
dom ( f ) \text{dom}(f) dom ( f )
∀ x , y ∈ dom ( f ) , λ ∈ [ 0 , 1 ] \forall \mathbf{x}, \mathbf{y} \in \text{dom}(f), \lambda \in [0,1] ∀ x , y ∈ dom ( f ) , λ ∈ [ 0 , 1 ]
f ( λ x + ( 1 − λ ) y ) ≤ λ f ( x ) + ( 1 − λ ) f ( y ) f(\lambda \mathbf{x} + (1-\lambda)\mathbf{y}) \leq \lambda f(\mathbf{x}) + (1-\lambda)f(\mathbf{y})
f ( λ x + ( 1 − λ ) y ) ≤ λ f ( x ) + ( 1 − λ ) f ( y )
Geometry : Line segment between graph points lies above graph.
First-Order Convexity
If f f f
f ( y ) ≥ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) f(\mathbf{y}) \geq f(\mathbf{x}) + \nabla f(\mathbf{x})^\top (\mathbf{y} - \mathbf{x})
f ( y ) ≥ f ( x ) + ∇ f ( x ) ⊤ ( y − x )
Geometry : Graph above tangent hyperplane.
Differentiable Functions
Definition : f f f x 0 \mathbf{x}_0 x 0 ∃ ∇ f ( x 0 ) \exists \nabla f(\mathbf{x}_0) ∃∇ f ( x 0 )
f ( x 0 + h ) ≈ f ( x 0 ) + ∇ f ( x 0 ) ⊤ h f(\mathbf{x}_0 + \mathbf{h}) \approx f(\mathbf{x}_0) + \nabla f(\mathbf{x}_0)^\top \mathbf{h}
f ( x 0 + h ) ≈ f ( x 0 ) + ∇ f ( x 0 ) ⊤ h
Global Differentiability : Differentiable everywhere → non-vertical tangents everywhere.
Convex Optimization
Formulation:
min x ∈ R d f ( x ) \min_{\mathbf{x} \in \mathbb{R}^d} f(\mathbf{x})
x ∈ R d min f ( x )
f f f R d \mathbb{R}^d R d x ∗ = arg min f ( x ) \mathbf{x}^* = \arg\min f(\mathbf{x}) x ∗ = arg min f ( x )
Gradient Descent
Core Idea
Update with negative gradient:
x k + 1 = x k − η k ∇ f ( x k ) \mathbf{x}_{k+1} = \mathbf{x}_k - \eta_k \nabla f(\mathbf{x}_k)
x k + 1 = x k − η k ∇ f ( x k )
Convergence Analysis
Lipschitz Convex Functions (Bounded Gradient)
Assumptions : ∥ ∇ f ( x ) ∥ ≤ B \|\nabla f(\mathbf{x})\| \leq B ∥∇ f ( x ) ∥ ≤ B ∥ x 0 − x ∗ ∥ ≤ R \|\mathbf{x}_0 - \mathbf{x}^*\| \leq R ∥ x 0 − x ∗ ∥ ≤ R Step Size : η = R B T \eta = \frac{R}{B\sqrt{T}} η = B T R Convergence Rate :
1 T ∑ t = 0 T − 1 [ f ( x t ) − f ( x ∗ ) ] ≤ R B T \frac{1}{T} \sum_{t=0}^{T-1} [f(\mathbf{x}_t) - f(\mathbf{x}^*)] \leq \frac{RB}{\sqrt{T}}
T 1 t = 0 ∑ T − 1 [ f ( x t ) − f ( x ∗ )] ≤ T RB
Advantage : Dimension-independent.Practice : Unknown B , R B, R B , R η \eta η
Smooth Convex Functions (Lipschitz Gradient)
Definition : f f f L L L
f ( y ) ≤ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) + L 2 ∥ x − y ∥ 2 f(\mathbf{y}) \leq f(\mathbf{x}) + \nabla f(\mathbf{x})^\top (\mathbf{y}-\mathbf{x}) + \frac{L}{2} \|\mathbf{x}-\mathbf{y}\|^2
f ( y ) ≤ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) + 2 L ∥ x − y ∥ 2
≡ ∥ ∇ f ( x ) − ∇ f ( y ) ∥ ≤ L ∥ x − y ∥ \|\nabla f(\mathbf{x}) - \nabla f(\mathbf{y})\| \leq L \|\mathbf{x}-\mathbf{y}\| ∥∇ f ( x ) − ∇ f ( y ) ∥ ≤ L ∥ x − y ∥ Step Size : η = 1 L \eta = \frac{1}{L} η = L 1 Convergence Rate :
f ( x T ) − f ( x ∗ ) ≤ L ∥ x 0 − x ∗ ∥ 2 2 T f(\mathbf{x}_T) - f(\mathbf{x}^*) \leq \frac{L \|\mathbf{x}_0 - \mathbf{x}^*\|^2}{2T}
f ( x T ) − f ( x ∗ ) ≤ 2 T L ∥ x 0 − x ∗ ∥ 2
Comparison : O ( 1 / ε ) O(1/\varepsilon) O ( 1/ ε ) O ( 1 / ε 2 ) O(1/\varepsilon^2) O ( 1/ ε 2 ) Practice : Unknown L L L f ( x t + 1 ) ≤ f ( x t ) − 1 2 L ∥ ∇ f ( x t ) ∥ 2 f(\mathbf{x}_{t+1}) \leq f(\mathbf{x}_t) - \frac{1}{2L} \|\nabla f(\mathbf{x}_t)\|^2 f ( x t + 1 ) ≤ f ( x t ) − 2 L 1 ∥∇ f ( x t ) ∥ 2
Subgradient Method
Subgradient Definition
For convex f f f g ∈ ∂ f ( x ) g \in \partial f(\mathbf{x}) g ∈ ∂ f ( x )
f ( y ) ≥ f ( x ) + g ⊤ ( y − x ) , ∀ y f(\mathbf{y}) \geq f(\mathbf{x}) + g^\top (\mathbf{y} - \mathbf{x}), \quad \forall \mathbf{y}
f ( y ) ≥ f ( x ) + g ⊤ ( y − x ) , ∀ y
Key Properties :
∂ f ( x ) = { ∇ f ( x ) } \partial f(\mathbf{x}) = \{\nabla f(\mathbf{x})\} ∂ f ( x ) = { ∇ f ( x )} Optimality: x ∗ \mathbf{x}^* x ∗ 0 ∈ ∂ f ( x ∗ ) 0 \in \partial f(\mathbf{x}^*) 0 ∈ ∂ f ( x ∗ )
Update Rule
x k + 1 = x k − η k g k , g k ∈ ∂ f ( x k ) \mathbf{x}_{k+1} = \mathbf{x}_k - \eta_k g_k, \quad g_k \in \partial f(\mathbf{x}_k)
x k + 1 = x k − η k g k , g k ∈ ∂ f ( x k )
Note : Not a descent method (e.g., oscillates for f ( x ) = ∣ x ∣ f(x)=|x| f ( x ) = ∣ x ∣
Convergence
Assumptions : f f f L L L
Fixed η \eta η : Limiting error ≤ f ∗ + L 2 η / 2 \leq f^* + L^2\eta/2 ≤ f ∗ + L 2 η /2
Diminishing η \eta η (∑ η k = ∞ \sum \eta_k = \infty ∑ η k = ∞ ∑ η k 2 < ∞ \sum \eta_k^2 < \infty ∑ η k 2 < ∞ f ∗ f^* f ∗ Convergence Rate :
f ( x best ( k ) ) − f ∗ ≤ R 2 + L 2 ∑ i = 1 k η i 2 2 ∑ i = 1 k η i f(\mathbf{x}_{\text{best}}^{(k)}) - f^* \leq \frac{R^2 + L^2 \sum_{i=1}^k \eta_i^2}{2 \sum_{i=1}^k \eta_i}
f ( x best ( k ) ) − f ∗ ≤ 2 ∑ i = 1 k η i R 2 + L 2 ∑ i = 1 k η i 2
where R = ∥ x 0 − x ∗ ∥ R = \|\mathbf{x}_0 - \mathbf{x}^*\| R = ∥ x 0 − x ∗ ∥ f best ( k ) = min i = 0 , … , k f ( x i ) f_{\text{best}}^{(k)} = \min_{i=0,\dots,k} f(\mathbf{x}_i) f best ( k ) = min i = 0 , … , k f ( x i )