#sdsc6015
English / 中文
Review
Click to expand
The general form of a convex optimization problem is:
min x ∈ R d f ( x ) \min_{x \in \mathbb{R}^d} f(x)
x ∈ R d min f ( x )
where f f f R d \mathbb{R}^d R d x ∗ x^* x ∗
x ∗ = arg min x ∈ R d f ( x ) x^* = \arg\min_{x \in \mathbb{R}^d} f(x)
x ∗ = arg x ∈ R d min f ( x )
The update rule for Gradient Descent (GD) is:
x k + 1 = x k − η k + 1 ∇ f ( x k ) x_{k+1} = x_k - \eta_{k+1} \nabla f(x_k)
x k + 1 = x k − η k + 1 ∇ f ( x k )
x k x_k x k
η k > 0 \eta_k > 0 η k > 0
x k + 1 x_{k+1} x k + 1
Definition:
A function f : dom ( f ) → R f: \text{dom}(f) \to \mathbb{R} f : dom ( f ) → R L > 0 L > 0 L > 0 x , y ∈ X ⊆ dom ( f ) x, y \in X \subseteq \text{dom}(f) x , y ∈ X ⊆ dom ( f )
f ( y ) ≤ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) + L 2 ∥ x − y ∥ 2 f(y) \leq f(x) + \nabla f(x)^\top (y - x) + \frac{L}{2} \|x - y\|^2
f ( y ) ≤ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) + 2 L ∥ x − y ∥ 2
Then f f f L L L
💡 Smoothness means the gradient of the function does not change too quickly, with an upper bound controlled by L L L
Definition:
For a convex function f : R d → R f: \mathbb{R}^d \to \mathbb{R} f : R d → R g g g x x x
f ( y ) ≥ f ( x ) + g ⊤ ( y − x ) , ∀ y f(y) \geq f(x) + g^\top (y - x), \quad \forall y
f ( y ) ≥ f ( x ) + g ⊤ ( y − x ) , ∀ y
The set of all subgradients is called the subdifferential :
∂ f ( x ) = { g ∈ R d ∣ g is a subgradient of f at x } \partial f(x) = \{ g \in \mathbb{R}^d \mid g \text{ is a subgradient of } f \text{ at } x \}
∂ f ( x ) = { g ∈ R d ∣ g is a subgradient of f at x }
🔍 For differentiable convex functions, the subdifferential is the gradient; for non-differentiable functions (e.g., ∣ x ∣ |x| ∣ x ∣
Subgradient Method:
The update rule is:
x k + 1 = x k − η k + 1 g k , g k ∈ ∂ f ( x k ) x_{k+1} = x_k - \eta_{k+1} g_k, \quad g_k \in \partial f(x_k)
x k + 1 = x k − η k + 1 g k , g k ∈ ∂ f ( x k )
Function Properties
Algorithm
Convergence Bound
Iterations (to achieve error ε \varepsilon ε
Convex, L L L
GD
f ( x best ( T ) ) − f ( x ∗ ) ≤ R L T f(x_{\text{best}}^{(T)}) - f(x^*) \leq \frac{RL}{\sqrt{T}} f ( x best ( T ) ) − f ( x ∗ ) ≤ T R L O ( R 2 L 2 ε 2 ) \mathcal{O}\left( \frac{R^2 L^2}{\varepsilon^2} \right) O ( ε 2 R 2 L 2 )
Convex, L L L
GD
f ( x best ( T ) ) − f ( x ∗ ) ≤ R 2 L 2 T f(x_{\text{best}}^{(T)}) - f(x^*) \leq \frac{R^2 L}{2T} f ( x best ( T ) ) − f ( x ∗ ) ≤ 2 T R 2 L O ( R 2 L 2 ε ) \mathcal{O}\left( \frac{R^2 L}{2\varepsilon} \right) O ( 2 ε R 2 L )
μ \mu μ L L L GD
f ( x best ( T ) ) − f ( x ∗ ) ≤ L 2 ( 1 − μ L ) T R 2 f(x_{\text{best}}^{(T)}) - f(x^*) \leq \frac{L}{2} \left(1 - \frac{\mu}{L}\right)^T R^2 f ( x best ( T ) ) − f ( x ∗ ) ≤ 2 L ( 1 − L μ ) T R 2 O ( L μ ln R 2 L 2 ε ) \mathcal{O}\left( \frac{L}{\mu} \ln \frac{R^2 L}{2\varepsilon} \right) O ( μ L ln 2 ε R 2 L )
Convex, L L L
Subgradient
f ( x best ( T ) ) − f ( x ∗ ) ≤ L R T f(x_{\text{best}}^{(T)}) - f(x^*) \leq \frac{LR}{\sqrt{T}} f ( x best ( T ) ) − f ( x ∗ ) ≤ T L R O ( R 2 L 2 ε 2 ) \mathcal{O}\left( \frac{R^2 L^2}{\varepsilon^2} \right) O ( ε 2 R 2 L 2 )
μ \mu μ ∣ g ∣ ≤ B |g| \leq B ∣ g ∣ ≤ B Subgradient
f ( x best ( T ) ) − f ( x ∗ ) ≤ 2 B 2 μ ( T + 1 ) f(x_{\text{best}}^{(T)}) - f(x^*) \leq \frac{2B^2}{\mu(T+1)} f ( x best ( T ) ) − f ( x ∗ ) ≤ μ ( T + 1 ) 2 B 2 O ( 2 B 2 μ ε ) \mathcal{O}\left( \frac{2B^2}{\mu\varepsilon} \right) O ( μ ε 2 B 2 )
Where:
R = ∥ x 0 − x ∗ ∥ R = \|x_0 - x^*\| R = ∥ x 0 − x ∗ ∥
x best ( T ) = arg min i = 0 , … , T f ( x i ) x_{\text{best}}^{(T)} = \arg\min_{i=0,\dots,T} f(x_i) x best ( T ) = arg min i = 0 , … , T f ( x i )
Strongly Convex Functions
Definition
A function f : dom ( f ) → R f: \text{dom}(f) \to \mathbb{R} f : dom ( f ) → R strongly convex if there exists a parameter μ > 0 \mu > 0 μ > 0 x , y ∈ dom ( f ) x, y \in \text{dom}(f) x , y ∈ dom ( f ) dom ( f ) \text{dom}(f) dom ( f )
f ( y ) ≥ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) + μ 2 ∥ y − x ∥ 2 f(y) \geq f(x) + \nabla f(x)^\top (y - x) + \frac{\mu}{2} \|y - x\|^2
f ( y ) ≥ f ( x ) + ∇ f ( x ) ⊤ ( y − x ) + 2 μ ∥ y − x ∥ 2
Here, ∇ f ( x ) \nabla f(x) ∇ f ( x ) f f f x x x f f f
For non-differentiable functions, the subgradient version of the definition is: for all g ∈ ∂ f ( x ) g \in \partial f(x) g ∈ ∂ f ( x )
f ( y ) ≥ f ( x ) + g ⊤ ( y − x ) + μ 2 ∥ y − x ∥ 2 f(y) \geq f(x) + g^\top (y - x) + \frac{\mu}{2} \|y - x\|^2
f ( y ) ≥ f ( x ) + g ⊤ ( y − x ) + 2 μ ∥ y − x ∥ 2
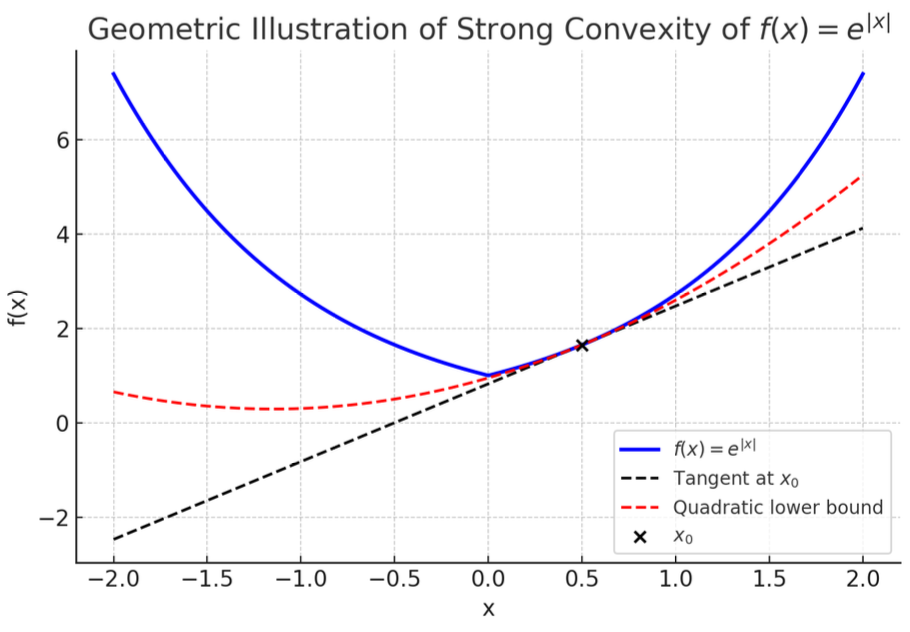
💡 Intuitive explanation : A strongly convex function has a value at any point x x x μ 2 ∥ y − x ∥ 2 \frac{\mu}{2} \|y - x\|^2 2 μ ∥ y − x ∥ 2
Key Properties
(1) Strong Convexity Implies Strict Convexity
If f f f μ \mu μ x ≠ y x \neq y x = y λ ∈ ( 0 , 1 ) \lambda \in (0,1) λ ∈ ( 0 , 1 )
f ( λ x + ( 1 − λ ) y ) < λ f ( x ) + ( 1 − λ ) f ( y ) f(\lambda x + (1-\lambda) y) < \lambda f(x) + (1-\lambda) f(y)
f ( λ x + ( 1 − λ ) y ) < λ f ( x ) + ( 1 − λ ) f ( y )
Proof outline (from supplementary notes p15):x ≠ y x \neq y x = y z = λ x + ( 1 − λ ) y z = \lambda x + (1-\lambda) y z = λ x + ( 1 − λ ) y
f ( x ) > f ( z ) + ∇ f ( z ) ⊤ ( x − z ) f ( y ) > f ( z ) + ∇ f ( z ) ⊤ ( y − z ) \begin{aligned}
f(x) &> f(z) + \nabla f(z)^\top (x - z) \\
f(y) &> f(z) + \nabla f(z)^\top (y - z)
\end{aligned}
f ( x ) f ( y ) > f ( z ) + ∇ f ( z ) ⊤ ( x − z ) > f ( z ) + ∇ f ( z ) ⊤ ( y − z )
Weighted average these two inequalities (weights λ \lambda λ 1 − λ 1-\lambda 1 − λ
λ f ( x ) + ( 1 − λ ) f ( y ) > f ( z ) \lambda f(x) + (1-\lambda) f(y) > f(z)
λ f ( x ) + ( 1 − λ ) f ( y ) > f ( z )
Thus proving strict convexity.
(2) Existence of a Unique Global Minimum
A strongly convex function has exactly one global minimum point x ∗ x^* x ∗ Proof outline (from supplementary notes p15):x ∗ x^* x ∗ ∇ f ( x ∗ ) = 0 \nabla f(x^*) = 0 ∇ f ( x ∗ ) = 0 0 ∈ ∂ f ( x ∗ ) 0 \in \partial f(x^*) 0 ∈ ∂ f ( x ∗ )
f ( y ) ≥ f ( x ∗ ) + μ 2 ∥ y − x ∗ ∥ 2 f(y) \geq f(x^*) + \frac{\mu}{2} \|y - x^*\|^2
f ( y ) ≥ f ( x ∗ ) + 2 μ ∥ y − x ∗ ∥ 2
When y ≠ x ∗ y \neq x^* y = x ∗ μ 2 ∥ y − x ∗ ∥ 2 > 0 \frac{\mu}{2} \|y - x^*\|^2 > 0 2 μ ∥ y − x ∗ ∥ 2 > 0 f ( y ) > f ( x ∗ ) f(y) > f(x^*) f ( y ) > f ( x ∗ ) x ∗ x^* x ∗
Examples
A typical example of a strongly convex function is f ( x ) = e ∣ x ∣ f(x) = e^{|x|} f ( x ) = e ∣ x ∣ μ \mu μ μ = 1 \mu = 1 μ = 1
Applications in Optimization
Strong convexity significantly improves the convergence rate of optimization algorithms. Discussed in two cases:
(1) Gradient Descent for Smooth and Strongly Convex Functions
If f f f L L L μ \mu μ η = 1 L \eta = \frac{1}{L} η = L 1
∥ x t + 1 − x ∗ ∥ 2 ≤ ( 1 − μ L ) ∥ x t − x ∗ ∥ 2 \|x_{t+1} - x^*\|^2 \leq \left(1 - \frac{\mu}{L} \right) \|x_t - x^*\|^2
∥ x t + 1 − x ∗ ∥ 2 ≤ ( 1 − L μ ) ∥ x t − x ∗ ∥ 2
Error decays exponentially:
f ( x T ) − f ( x ∗ ) ≤ L 2 ( 1 − μ L ) T ∥ x 0 − x ∗ ∥ 2 f(x_T) - f(x^*) \leq \frac{L}{2} \left(1 - \frac{\mu}{L} \right)^T \|x_0 - x^*\|^2
f ( x T ) − f ( x ∗ ) ≤ 2 L ( 1 − L μ ) T ∥ x 0 − x ∗ ∥ 2
Proof:
From gradient descent update: x t + 1 = x t − η ∇ f ( x t ) x_{t+1} = x_t - \eta \nabla f(x_t) x t + 1 = x t − η ∇ f ( x t )
∥ x t + 1 − x ∗ ∥ 2 = ∥ x t − η ∇ f ( x t ) − x ∗ ∥ 2 = ∥ x t − x ∗ ∥ 2 − 2 η ∇ f ( x t ) ⊤ ( x t − x ∗ ) + η 2 ∥ ∇ f ( x t ) ∥ 2 \|x_{t+1} - x^*\|^2 = \|x_t - \eta \nabla f(x_t) - x^*\|^2 = \|x_t - x^*\|^2 - 2\eta \nabla f(x_t)^\top (x_t - x^*) + \eta^2 \|\nabla f(x_t)\|^2
∥ x t + 1 − x ∗ ∥ 2 = ∥ x t − η ∇ f ( x t ) − x ∗ ∥ 2 = ∥ x t − x ∗ ∥ 2 − 2 η ∇ f ( x t ) ⊤ ( x t − x ∗ ) + η 2 ∥∇ f ( x t ) ∥ 2
By strong convexity:
∇ f ( x t ) ⊤ ( x t − x ∗ ) ≥ f ( x t ) − f ( x ∗ ) + μ 2 ∥ x t − x ∗ ∥ 2 \nabla f(x_t)^\top (x_t - x^*) \geq f(x_t) - f(x^*) + \frac{\mu}{2} \|x_t - x^*\|^2
∇ f ( x t ) ⊤ ( x t − x ∗ ) ≥ f ( x t ) − f ( x ∗ ) + 2 μ ∥ x t − x ∗ ∥ 2
Substitute:
∥ x t + 1 − x ∗ ∥ 2 ≤ ∥ x t − x ∗ ∥ 2 − 2 η ( f ( x t ) − f ( x ∗ ) + μ 2 ∥ x 极 − x ∗ ∥ 2 ) + η 极 ∥ ∇ f ( x t ) ∥ 2 \|x_{t+1} - x^*\|^2 \leq \|x_t - x^*\|^2 - 2\eta \left( f(x_t) - f(x^*) + \frac{\mu}{2} \|x极 - x^*\|^2 \right) + \eta^极 \|\nabla f(x_t)\|^2
∥ x t + 1 − x ∗ ∥ 2 ≤ ∥ x t − x ∗ ∥ 2 − 2 η ( f ( x t ) − f ( x ∗ ) + 2 μ ∥ x 极 − x ∗ ∥ 2 ) + η 极 ∥∇ f ( x t ) ∥ 2
Rearrange:
∥ x t + 1 − x ∗ ∥ 2 ≤ ( 1 − μ η ) ∥ x t − x ∗ ∥ 2 − 2 η ( f ( x t ) − f ( x ∗ ) ) + η 2 ∥ ∇ f ( x t ) ∥ 2 \|x_{t+1} - x^*\|^2 \leq (1 - \mu \eta) \|x_t - x^*\|^2 - 2\eta (f(x_t) - f(x^*)) + \eta^2 \|\nabla f(x_t)\|^2
∥ x t + 1 − x ∗ ∥ 2 ≤ ( 1 − μ η ) ∥ x t − x ∗ ∥ 2 − 2 η ( f ( x t ) − f ( x ∗ )) + η 2 ∥∇ f ( x t ) ∥ 2
Now set η = 1 / L \eta = 1/L η = 1/ L
f ( x t + 1 ) ≤ f ( x t ) − 1 2 L ∥ ∇ f ( x t ) ∥ 2 f(x_{t+1}) \leq f(x_t) - \frac{1}{2L} \|\nabla f(x_t)\|^2
f ( x t + 1 ) ≤ f ( x t ) − 2 L 1 ∥∇ f ( x t ) ∥ 2
Thus, − 1 2 L ∥ ∇ f ( x t ) ∥ 2 ≤ f ( x 极 + 1 ) − f ( x t ) -\frac{1}{2L} \|\nabla f(x_t)\|^2 \leq f(x_{极+1}) - f(x_t) − 2 L 1 ∥∇ f ( x t ) ∥ 2 ≤ f ( x 极 + 1 ) − f ( x t ) η 2 ∥ ∇ f ( x t ) ∥ 2 \eta^2 \|\nabla f(x_t)\|^2 η 2 ∥∇ f ( x t ) ∥ 2
Actually, from smoothness:
f ( x ∗ ) ≤ f ( x t ) − 1 2 L ∥ ∇ f ( x t ) ∥ 2 f(x^*) \leq f(x_t) - \frac{1}{2L} \|\nabla f(x_t)\|^2
f ( x ∗ ) ≤ f ( x t ) − 2 L 1 ∥∇ f ( x t ) ∥ 2
So ∥ ∇ f ( x t ) ∥ 2 ≤ 2 L ( f ( x t ) − f ( x ∗ ) ) \|\nabla f(x_t)\|^2 \leq 2L (f(x_t) - f(x^*)) ∥∇ f ( x t ) ∥ 2 ≤ 2 L ( f ( x t ) − f ( x ∗ ))
Substitute:
η 2 ∥ ∇ f ( x t ) ∥ 2 = 1 L 2 ∥ ∇ f ( x t ) ∥ 极 ≤ 2 L ( f ( x t ) − f ( x ∗ ) ) \eta^2 \|\nabla f(x_t)\|^2 = \frac{1}{L^2} \|\nabla f(x_t)\|^极 \leq \frac{2}{L} (f(x_t) - f(x^*))
η 2 ∥∇ f ( x t ) ∥ 2 = L 2 1 ∥∇ f ( x t ) ∥ 极 ≤ L 2 ( f ( x t ) − f ( x ∗ ))
Then:
∥ x t + 1 − x ∗ ∥ 2 ≤ ( 1 − μ η ) ∥ x t − x ∗ ∥ 2 − 2 η ( f ( x t ) − f ( x ∗ ) ) + 2 L ( f ( x t ) − f ( x ∗ ) ) \|x_{t+1} - x^*\|^2 \leq (1 - \mu \eta) \|x_t - x^*\|^2 - 2\eta (f(x_t) - f(x^*)) + \frac{2}{L} (f(x_t) - f(x^*))
∥ x t + 1 − x ∗ ∥ 2 ≤ ( 1 − μ η ) ∥ x t − x ∗ ∥ 2 − 2 η ( f ( x t ) − f ( x ∗ )) + L 2 ( f ( x t ) − f ( x ∗ ))
Since η = 1 / L \eta = 1/L η = 1/ L − 2 η + 2 L = 0 -2\eta + \frac{2}{L} = 0 − 2 η + L 2 = 0
∥ x t + 1 − x ∗ ∥ 2 ≤ ( 1 − μ L ) ∥ x t − x ∗ ∥ 2 \|x_{t+1} - x^*\|^2 \leq (1 - \frac{\mu}{L}) \|x_t - x^*\|^2
∥ x t + 1 − x ∗ ∥ 2 ≤ ( 1 − L μ ) ∥ x t − x ∗ ∥ 2
This proves the first part.
For the second part, by smoothness:
f ( x T ) − 极 f ( x ∗ ) ≤ L 2 ∥ x T − x ∗ ∥ 2 ≤ L 2 ( 1 − μ L ) T ∥ x 0 − x ∗ ∥ 2 f(x_T) -极 f(x^*) \leq \frac{L}{2} \|x_T - x^*\|^2 \leq \frac{L}{2} \left(1 - \frac{\mu}{L}\right)^T \|x_0 - x^*\|^2
f ( x T ) − 极 f ( x ∗ ) ≤ 2 L ∥ x T − x ∗ ∥ 2 ≤ 2 L ( 1 − L μ ) T ∥ x 0 − x ∗ ∥ 2
Q.E.D.
Iteration requirement : To achieve error ε \varepsilon ε
T ≥ L μ ln ( R 2 L 2 ε ) , where R = ∥ x 0 − x ∗ ∥ T \geq \frac{L}{\mu} \ln \left( \frac{R^2 L}{2\varepsilon} \right), \quad \text{where } R = \|x_0 - x^*\|
T ≥ μ L ln ( 2 ε R 2 L ) , where R = ∥ x 0 − x ∗ ∥
This is much faster than the non-strongly convex case (e.g., O ( 1 / ε ) \mathcal{O}(1/\varepsilon) O ( 1/ ε ) O ( e − T ) \mathcal{O}(e^{-T}) O ( e − T )
(2) Subgradient Method for Strongly Convex Functions
If f f f μ \mu μ ∥ g t ∥ ≤ B \|g_t\| \leq B ∥ g t ∥ ≤ B g t ∈ ∂ f ( x t ) g_t \in \partial f(x_t) g t ∈ ∂ f ( x t )
η t = 2 μ ( t + 1 ) \eta_t = \frac{2}{\mu(t + 1)}
η t = μ ( t + 1 ) 2
And compute the weighted average point:
x ˉ T = 2 T ( T + 1 ) ∑ t = 1 T t ⋅ x t \bar{x}_T = \frac{2}{T(T+1)} \sum_{t=1}^T t \cdot x_t
x ˉ T = T ( T + 1 ) 2 t = 1 ∑ T t ⋅ x t
The convergence rate is:
f ( x ˉ T ) − f ( x ∗ ) ≤ 2 B 2 μ ( T + 1 ) f(\bar{x}_T) - f(x^*) \leq \frac{2B^2}{\mu(T + 1)}
f ( x ˉ T ) − f ( x ∗ ) ≤ μ ( T + 1 ) 2 B 2
Proof:
From subgradient update: x t + 1 = x t − η t g t x_{t+1} = x_t - \eta_t g_t x t + 1 = x t − η t g t g t ∈ ∂ f ( x t ) g_t \in \partial f(x_t) g t ∈ ∂ f ( x t )
∥ x t + 1 − x ∗ ∥ 2 = ∥ x t − η t g t − x ∗ ∥ 2 = ∥ x t − x ∗ ∥ 2 − 2 η t g t ⊤ ( x t − x ∗ ) + η t 2 ∥ g t ∥ 2 \|x_{t+1} - x^*\|^2 = \|x_t - \eta_t g_t - x^*\|^2 = \|x_t - x^*\|^2 - 2\eta_t g_t^\top (x_t - x^*) + \eta_t^2 \|g_t\|^2
∥ x t + 1 − x ∗ ∥ 2 = ∥ x t − η t g t − x ∗ ∥ 2 = ∥ x t − x ∗ ∥ 2 − 2 η t g t ⊤ ( x t − x ∗ ) + η t 2 ∥ g t ∥ 2
By strong convexity:
g t ⊤ ( x t − x ∗ ) ≥ f ( x t ) − f ( x ∗ ) + μ 2 ∥ x t − x ∗ ∥ 2 g_t^\top (x_t - x^*) \geq f(x_t) - f(x^*) + \frac{\mu}{2} \|x_t - x^*\|^2
g t ⊤ ( x t − x ∗ ) ≥ f ( x t ) − f ( x ∗ ) + 2 μ ∥ x t − x ∗ ∥ 2
Substitute:
∥ x t + 极 − x ∗ ∥ 2 ≤ ∥ x t − x ∗ ∥ 2 − 2 η t ( f ( x t ) − f ( x ∗ ) + μ 2 ∥ x t − x ∗ ∥ 2 ) + η t 2 ∥ g t ∥ 2 \|x_{t+极} - x^*\|^2 \leq \|x_t - x^*\|^2 - 2\eta_t \left( f(x_t) - f(x^*) + \frac{\mu}{2} \|x_t - x^*\|^2 \right) + \eta_t^2 \|g_t\|^2
∥ x t + 极 − x ∗ ∥ 2 ≤ ∥ x t − x ∗ ∥ 2 − 2 η t ( f ( x t ) − f ( x ∗ ) + 2 μ ∥ x t − x ∗ ∥ 2 ) + η t 2 ∥ g t ∥ 2
Rearrange:
∥ x t + 1 − x ∗ ∥ 2 ≤ ( 1 − μ η t ) ∥ x t − x ∗ ∥ 2 − 2 η t ( f ( x t ) − f ( x ∗ ) ) + η t 2 B 2 \|x_{t+1} - x^*\|^2 \leq (1 - \mu \eta_t) \|x_t - x^*\|^2 - 2\eta_t (f(x_t) - f(x^*)) + \eta_t^2 B^2
∥ x t + 1 − x ∗ ∥ 2 ≤ ( 1 − μ η t ) ∥ x t − x ∗ ∥ 2 − 2 η t ( f ( x t ) − f ( x ∗ )) + η t 2 B 2
Now move terms:
2 η t ( f ( x t ) − f ( x ∗ ) ) ≤ ( 1 − μ η t ) ∥ x t − x ∗ ∥ 2 − ∥ x t + 1 − x ∗ ∥ 2 + η t 2 B 2 2\eta_t (f(x_t) - f(x^*)) \leq (1 - \mu \eta_t) \|x_t - x^*\|^2 - \|x_{t+1} - x^*\|^2 + \eta_t^2 B^2
2 η t ( f ( x t ) − f ( x ∗ )) ≤ ( 1 − μ η t ) ∥ x t − x ∗ ∥ 2 − ∥ x t + 1 − x ∗ ∥ 2 + η t 2 B 2
Substitute step size η t = 2 μ ( t + 1 ) \eta_t = \frac{2}{\mu(t+1)} η t = μ ( t + 1 ) 2 1 − μ η t = 1 − 2 t + 1 = t − 1 t + 1 1 - \mu \eta_t = 1 - \frac{2}{t+1} = \frac{t-1}{t+1} 1 − μ η t = 1 − t + 1 2 = t + 1 t − 1
Multiply both sides by t t t
2 t η t ( f ( x t ) − f ( x ∗ ) ) ≤ t ( 1 − μ η t ) ∥ x t − x ∗ ∥ 2 − t ∥ x t + 1 − x ∗ ∥ 2 + t η t 2 B 2 2t \eta_t (f(x_t) - f(x^*)) \leq t(1 - \mu \eta_t) \|x_t - x^*\|^2 - t \|x_{t+1} - x^*\|^2 + t \eta_t^2 B^2
2 t η t ( f ( x t ) − f ( x ∗ )) ≤ t ( 1 − μ η t ) ∥ x t − x ∗ ∥ 2 − t ∥ x t + 1 − x ∗ ∥ 2 + t η t 2 B 2
Note t ( 1 − μ η t ) = t ⋅ t − 1 t + 1 = t ( t − 1 ) t + 1 t(1 - \mu \eta_t) = t \cdot \frac{t-1}{t+1} = \frac{t(t-1)}{t+1} t ( 1 − μ η t ) = t ⋅ t + 1 t − 1 = t + 1 t ( t − 1 ) t η t 2 = t ⋅ 4 μ 2 ( t + 1 ) 2 = 4 t μ 2 ( t + 1 ) 2 t \eta_t^2 = t \cdot \frac{4}{\mu^2 (t+1)^2} = \frac{4t}{\mu^2 (t+1)^2} t η t 2 = t ⋅ μ 2 ( t + 1 ) 2 4 = μ 2 ( t + 1 ) 2 4 t
But more directly, observe:
t ( 1 − μ η t ) = t ( t − 1 ) t + 1 , and ( t + 1 ) ∥ x t + 1 − x ∗ ∥ 2 might appear t(1 - \mu \eta_t) = \frac{t(t-1)}{t+1}, \quad \text{and} \quad (t+1) \|x_{t+1} - x^*\|^2 \text{ might appear}
t ( 1 − μ η t ) = t + 1 t ( t − 1 ) , and ( t + 1 ) ∥ x t + 1 − x ∗ ∥ 2 might appear
Actually, from the original inequality:
2 η t ( f ( x t ) − f ( x ∗ ) ) ≤ η t 2 B 2 2 + 1 2 η t ( ∥ x t − x ∗ ∥ 2 − ∥ x t + 1 − x ∗ ∥ 2 ) − μ 2 ∥ x t − x ∗ ∥ 2 2\eta_t (f(x_t) - f(x^*)) \leq \frac{\eta_t^2 B^2}{2} + \frac{1}{2\eta_t} \left( \|x_t - x^*\|^2 - \|x_{t+1} - x^*\|^2 \right) - \frac{\mu}{2} \|x_t - x^*\|^2
2 η t ( f ( x t ) − f ( x ∗ )) ≤ 2 η t 2 B 2 + 2 η t 1 ( ∥ x t − x ∗ ∥ 2 − ∥ x t + 1 − x ∗ ∥ 2 ) − 2 μ ∥ x t − x ∗ ∥ 2
But the course material uses another approach.
According to the course material proof:
f ( x t ) − f ( x ∗ ) ≤ B 2 η t 2 + η t − 1 − μ 2 ∥ x t − x ∗ ∥ 2 − η t − 1 2 ∥ x t + 1 − x ∗ ∥ 2 f(x_t) - f(x^*) \leq \frac{B^2 \eta_t}{2} + \frac{\eta_t^{-1} - \mu}{2} \|x_t - x^*\|^2 - \frac{\eta_t^{-1}}{2} \|x_{t+1} - x^*\|^2
f ( x t ) − f ( x ∗ ) ≤ 2 B 2 η t + 2 η t − 1 − μ ∥ x t − x ∗ ∥ 2 − 2 η t − 1 ∥ x t + 1 − x ∗ ∥ 2
Substitute η t = 2 μ ( t + 1 ) \eta_t = \frac{2}{\mu(t+1)} η t = μ ( t + 1 ) 2 η t − 1 = μ ( t + 1 ) 2 \eta_t^{-1} = \frac{\mu(t+1)}{2} η t − 1 = 2 μ ( t + 1 )
So:
f ( x t ) − f ( x ∗ ) ≤ B 2 2 ⋅ 2 μ ( t + 1 ) + 1 2 ( μ ( t + 1 ) 2 − μ ) ∥ x t − x ∗ ∥ 2 − 1 2 ⋅ μ ( t + 1 ) 2 ∥ x t + 1 − x ∗ ∥ 2 f(x_t) - f(x^*) \leq \frac{B^2}{2} \cdot \frac{2}{\mu(t+1)} + \frac{1}{2} \left( \frac{\mu(t+1)}{2} - \mu \right) \|x_t - x^*\|^2 - \frac{1}{2} \cdot \frac{\mu(t+1)}{2} \|x_{t+1} - x^*\|^2
f ( x t ) − f ( x ∗ ) ≤ 2 B 2 ⋅ μ ( t + 1 ) 2 + 2 1 ( 2 μ ( t + 1 ) − μ ) ∥ x t − x ∗ ∥ 2 − 2 1 ⋅ 2 μ ( t + 1 ) ∥ x t + 1 − x ∗ ∥ 2
Simplify:
f ( x t ) − f ( x ∗ ) ≤ B 2 μ ( t + 1 ) + μ 4 ( ( t + 1 ) − 2 ) ∥ x t − x ∗ ∥ 2 − μ ( t + 1 ) 4 ∥ x t + 1 − x ∗ ∥ 2 f(x_t) - f(x^*) \leq \frac{B^2}{\mu(t+1)} + \frac{\mu}{4} \left( (t+1) - 2 \right) \|x_t - x^*\|^2 - \frac{\mu(t+1)}{4} \|x_{t+1} - x^*\|^2
f ( x t ) − f ( x ∗ ) ≤ μ ( t + 1 ) B 2 + 4 μ ( ( t + 1 ) − 2 ) ∥ x t − x ∗ ∥ 2 − 4 μ ( t + 1 ) ∥ x t + 1 − x ∗ ∥ 2
i.e.:
f(x_t) - f(x^*) \leq \frac{B^2}{\极\mu(t+1)} + \frac{\mu}{4} (t-1) \|x_t - x^*\|^2 - \frac{\mu(t+1)}{4} \|x_{t+1} - x^*\|^2
Multiply both sides by t t t
t ( f ( x t ) − f ( x ∗ ) ) ≤ t B 2 μ ( t + 1 ) + μ 4 ( t ( t − 1 ) ∥ x t − x ∗ ∥ 2 − t ( t + 1 ) ∥ x t + 1 − x ∗ ∥ 2 ) t (f(x_t) - f(x^*)) \leq \frac{t B^2}{\mu(t+1)} + \frac{\mu}{4} \left( t(t-1) \|x_t - x^*\|^2 - t(t+1) \|x_{t+1} - x^*\|^2 \right)
t ( f ( x t ) − f ( x ∗ )) ≤ μ ( t + 1 ) t B 2 + 4 μ ( t ( t − 1 ) ∥ x t − x ∗ ∥ 2 − t ( t + 1 ) ∥ x t + 1 − x ∗ ∥ 2 )
Sum from t = 1 t=1 t = 1 T T T
\sum_{t=1}^T t (f(x_t) - f(x^*)) \leq \sum_{t=1}^T \frac{t B^2}{\mu(t+1)} + \frac{\mu}{4} \left( \sum_{t=1}^T [t(t-1) \|x_t - x^*\|^2 - t(t+1) \极\|x_{t+1} - x^*\|^2] \right)
The second term on the right is a telescoping sum:
∑ t = 1 T [ t ( t − 1 ) ∥ x t − x ∗ ∥ 2 − t ( t + 1 ) ∥ x t + 1 − x ∗ ∥ 2 ] = − T ( T + 1 ) ∥ x T + 1 − x ∗ ∥ 2 ≤ 0 \sum_{t=1}^T [t(t-1) \|x_t - x^*\|^2 - t(t+1) \|x_{t+1} - x^*\|^2] = - T(T+1) \|x_{T+1} - x^*\|^2 \leq 0
t = 1 ∑ T [ t ( t − 1 ) ∥ x t − x ∗ ∥ 2 − t ( t + 1 ) ∥ x t + 1 − x ∗ ∥ 2 ] = − T ( T + 1 ) ∥ x T + 1 − x ∗ ∥ 2 ≤ 0
Because when t = 1 t=1 t = 1 1 ⋅ 0 ⋅ ∥ x 1 − x ∗ ∥ 2 = 0 1 \cdot 0 \cdot \|x_1 - x^*\|^2 = 0 1 ⋅ 0 ⋅ ∥ x 1 − x ∗ ∥ 2 = 0
So:
∑ t = 1 T t ( f ( x t ) − f ( x ∗ ) ) ≤ ∑ t = 1 T t B 2 μ ( t + 1 ) ≤ T B 2 μ \sum_{t=1}^T t (f(x_t) - f(x^*)) \leq \sum_{t=1}^T \frac{t B^2}{\mu(t+1)} \leq \frac{T B^2}{\mu}
t = 1 ∑ T t ( f ( x t ) − f ( x ∗ )) ≤ t = 1 ∑ T μ ( t + 1 ) t B 2 ≤ μ T B 2
By convexity, the weighted average satisfies:
f ( 2 T ( T + 1 ) ∑ t = 1 T t x t ) ≤ 2 T ( T + 1 ) ∑ t = 1 T t f ( x t ) f\left( \frac{2}{T(T+1)} \sum_{t=1}^T t x_t \right) \leq \frac{2}{T(T+1)} \sum_{t=1}^T t f(x_t)
f ( T ( T + 1 ) 2 t = 1 ∑ T t x t ) ≤ T ( T + 1 ) 2 t = 1 ∑ T t f ( x t )
So:
f ( 2 T ( T + 1 ) ∑ t = 1 T t x t ) − f ( x ∗ ) ≤ 2 T ( T + 1 ) ∑ t = 1 T t ( f ( x t ) − f ( x ∗ ) ) ≤ 2 T ( T + 1 ) ⋅ T B 2 μ = 2 B 2 μ ( T + 1 ) f\left( \frac{2}{T(T+1)} \sum_{t=1}^T t x_t \right) - f(x^*) \leq \frac{2}{T(T+1)} \sum_{t=1}^T t (f(x_t) - f(x^*)) \leq \frac{2}{T(T+1)} \cdot \frac{T B^2}{\mu} = \frac{2 B^2}{\mu (T+1)}
f ( T ( T + 1 ) 2 t = 1 ∑ T t x t ) − f ( x ∗ ) ≤ T ( T + 1 ) 2 t = 1 ∑ T t ( f ( x t ) − f ( x ∗ )) ≤ T ( T + 1 ) 2 ⋅ μ T B 2 = μ ( T + 1 ) 2 B 2
Q.E.D.
Iteration requirement : To achieve error ε \varepsilon ε O ( B 2 μ ε ) \mathcal{O}\left( \frac{B^2}{\mu \varepsilon} \right) O ( μ ε B 2 )
🔍 Note: Weighted averaging helps stabilize convergence and avoid subgradient oscillation. But the subgradient method is not a descent method, so averaging is necessary.
Projected Gradient Descent
Constrained Optimization Problem
min x ∈ X f ( x ) \min_{x \in X} f(x)
x ∈ X min f ( x )
where X ⊆ R d X \subseteq \mathbb{R}^d X ⊆ R d
Projection Operator
The projection onto X X X
Π X ( y ) = arg min x ∈ X ∥ x − y ∥ \Pi_X(y) = \arg\min_{x \in X} \|x - y\|
Π X ( y ) = arg x ∈ X min ∥ x − y ∥
Update Rule
y t + 1 = x t − η t ∇ f ( x t ) x t + 1 = Π X ( y t + 1 ) \begin{aligned}
y_{t+1} &= x_t - \eta_t \nabla f(x_t) \\
x_{t+1} &= \Pi_X(y_{t+1})
\end{aligned}
y t + 1 x t + 1 = x t − η t ∇ f ( x t ) = Π X ( y t + 1 )
Projection Properties
( x − Π X ( y ) ) ⊤ ( y − Π X ( y ) ) ≤ 0 (x - \Pi_X(y))^\top (y - \Pi_X(y)) \leq 0 ( x − Π X ( y ) ) ⊤ ( y − Π X ( y )) ≤ 0 x ∈ X x \in X x ∈ X
∥ x − Π X ( y ) ∥ 2 + ∥ y − Π X ( y ) ∥ 2 ≤ ∥ x − y ∥ 2 \|x - \Pi_X(y)\|^2 + \|y - \Pi_X(y)\|^2 \leq \|x - y\|^2 ∥ x − Π X ( y ) ∥ 2 + ∥ y − Π X ( y ) ∥ 2 ≤ ∥ x − y ∥ 2 x ∈ X x \in X x ∈ X
Proof:
Since Π X ( y ) \Pi_X(y) Π X ( y ) ∥ x − y ∥ 2 \|x - y\|^2 ∥ x − y ∥ 2 X X X x ∈ X x \in X x ∈ X
( Π X ( y ) − y ) ⊤ ( x − Π X ( y ) ) ≥ 0 (\Pi_X(y) - y)^\top (x - \Pi_X(y)) \geq 0
( Π X ( y ) − y ) ⊤ ( x − Π X ( y )) ≥ 0
i.e., ( x − Π X ( y ) ) ⊤ ( y − Π X ( y ) ) ≤ 0 (x - \Pi_X(y))^\top (y - \Pi_X(y)) \leq 0 ( x − Π X ( y ) ) ⊤ ( y − Π X ( y )) ≤ 0
From 1, we have:
∥ x − y ∥ 2 = ∥ x − Π X ( y ) + Π X ( y ) − y ∥ 2 = ∥ x − Π X ( y ) ∥ 2 + ∥ Π X ( y ) − y ∥ 2 + 2 ( x − Π X ( y ) ) ⊤ ( Π X ( y ) − y ) \|x - y\|^2 = \|x - \Pi_X(y) + \Pi_X(y) - y\|^2 = \|x - \Pi_X(y)\|^2 + \|\Pi_X(y) - y\|^2 + 2 (x - \Pi_X(y))^\top (\Pi_X(y) - y)
∥ x − y ∥ 2 = ∥ x − Π X ( y ) + Π X ( y ) − y ∥ 2 = ∥ x − Π X ( y ) ∥ 2 + ∥ Π X ( y ) − y ∥ 2 + 2 ( x − Π X ( y ) ) ⊤ ( Π X ( y ) − y )
Since ( x − Π X ( y ) ) ⊤ ( Π X ( y ) − y ) ≥ 0 (x - \Pi_X(y))^\top (\Pi_X(y) - y) \geq 0 ( x − Π X ( y ) ) ⊤ ( Π X ( y ) − y ) ≥ 0
∥ x − y ∥ 2 ≥ ∥ x − Π X ( y ) ∥ 2 + ∥ Π X ( y ) − y ∥ 2 \|x - y\|^2 \geq \|x - \Pi_X(y)\|^2 + \|\Pi_X(y) - y\|^2
∥ x − y ∥ 2 ≥ ∥ x − Π X ( y ) ∥ 2 + ∥ Π X ( y ) − y ∥ 2
i.e., property 2.
Convergence Rate
The convergence rate of projected gradient descent is the same as the unconstrained case, depending on function properties:
If f f f L L L X X X O ( 1 / T ) O(1/\sqrt{T}) O ( 1/ T ) O ( 1 / ε 2 ) O(1/\varepsilon^2) O ( 1/ ε 2 )
If f f f L L L X X X O ( 1 / T ) O(1/T) O ( 1/ T ) O ( 1 / ε ) O(1/\varepsilon) O ( 1/ ε )
If f f f μ \mu μ L L L X X X O ( e − c T ) O(e^{-c T}) O ( e − c T ) O ( log ( 1 / ε ) ) O(\log(1/\varepsilon)) O ( log ( 1/ ε ))
Proof sketch : Similar to unconstrained proof, but use projection properties to bound ∥ x t + 1 − x ∗ ∥ 2 \|x_{t+1} - x^*\|^2 ∥ x t + 1 − x ∗ ∥ 2
y t + 1 = x t − η ∇ f ( x t ) y_{t+1} = x_t - \eta \nabla f(x_t)
y t + 1 = x t − η ∇ f ( x t )
By projection property 2:
∥ x t + 1 − x ∗ ∥ 2 ≤ ∥ y t + 1 − x ∗ ∥ 2 − ∥ y t + 1 − x t + 1 ∥ 2 ≤ ∥ y t + 1 − x ∗ ∥ 2 \|x_{t+1} - x^*\|^2 \leq \|y_{t+1} - x^*\|^2 - \|y_{t+1} - x_{t+1}\|^2 \leq \|y_{t+1} - x^*\|^2
∥ x t + 1 − x ∗ ∥ 2 ≤ ∥ y t + 1 − x ∗ ∥ 2 − ∥ y t + 1 − x t + 1 ∥ 2 ≤ ∥ y t + 1 − x ∗ ∥ 2
Then analyze similarly to unconstrained.
Summary Table
Function Properties
Algorithm
Convergence Rate
Iterations
Convex, L L L
Gradient Descent
f ( x best ( T ) ) − f ( x ∗ ) ≤ R L T f(x_{\text{best}}^{(T)}) - f(x^*) \leq \frac{RL}{\sqrt{T}} f ( x best ( T ) ) − f ( x ∗ ) ≤ T R L O ( 1 / ε 2 ) O(1/\varepsilon^2) O ( 1/ ε 2 )
Convex, L L L
Gradient Descent
f ( x best ( T ) ) − f ( x ∗ ) ≤ R 2 L 2 T f(x_{\text{best}}^{(T)}) - f(x^*) \leq \frac{R^2 L}{2T} f ( x best ( T ) ) − f ( x ∗ ) ≤ 2 T R 2 L O ( 1 / ε ) O(1/\varepsilon) O ( 1/ ε )
Convex, L L L
Subgradient Method
f ( x best ( T ) ) − f ( x ∗ ) ≤ L R T f(x_{\text{best}}^{(T)}) - f(x^*) \leq \frac{LR}{\sqrt{T}} f ( x best ( T ) ) − f ( x ∗ ) ≤ T L R O ( 1 / ε 2 ) O(1/\varepsilon^2) O ( 1/ ε 2 )
μ \mu μ L L L Gradient Descent
f ( x best ( T ) ) − f ( x ∗ ) ≤ R L 2 ( 1 − μ L ) T f(x_{\text{best}}^{(T)}) - f(x^*) \leq \frac{RL}{2}(1 - \frac{\mu}{L})^T f ( x best ( T ) ) − f ( x ∗ ) ≤ 2 R L ( 1 − L μ ) T O ( log ( 1 / ε ) ) O(\log(1/\varepsilon)) O ( log ( 1/ ε ))
μ \mu μ ∣ g ∣ ≤ B |g| \leq B ∣ g ∣ ≤ B Subgradient Method
f ( x best ( T ) ) − f ( x ∗ ) ≤ 2 B 2 μ ( T + 1 ) f(x_{\text{best}}^{(T)}) - f(x^*) \leq \frac{2B^2}{\mu(T+1)} f ( x best ( T ) ) − f ( x ∗ ) ≤ μ ( T + 1 ) 2 B 2 O ( 1 / ε ) O(1/\varepsilon) O ( 1/ ε )
Where R = ∥ x 0 − x ∗ ∥ R = \|x_0 - x^*\| R = ∥ x 0 − x ∗ ∥
Note: In practice, step size selection is crucial for convergence. For unknown parameters, adaptive step size strategies may be needed.
Additional Notes
Conflict between Strong Convexity and Lipschitz :f ( x ) = x f(x) = \sqrt{x} f ( x ) = x x = 0 x=0 x = 0
Relationship between Subgradient Norm and Lipschitz :
Lipschitz continuity ⇒ \Rightarrow ⇒
Bounded subgradient ⇏ \not\Rightarrow ⇒
Optimality :