
SDSC6015 Course 5-Mirror Descent and SDG
#sdsc6015
English / 中文
Mirror Descent
Motivation
Consider the simplex-constrained optimization problem:
where the simplex . Assume the gradient’s infinity norm is bounded: .
-
Notation: is the optimization variable, is the dimension, is the probability simplex.
-
Geometric Interpretation: The simplex is the space of probability distributions; constrained optimization aims to minimize the loss under probability constraints.
-
Convergence Rate Comparison:
- GD:
- Mirror Descent: , superior in high-dimensional problems.
Preliminaries
-
Dual Norm: .
-
Function Properties:
- -Lipschitz: for .
- -smooth: Gradient satisfies Lipschitz condition.
- -strongly convex: Function has a lower-bounding quadratic term.
Mirror Descent Algorithm
Iteration format:
where , is the mirror potential, is the projection based on Bregman divergence.
-
Notation: is strictly convex and continuously differentiable, is the Bregman divergence.
-
Geometric Interpretation: Transforms the problem into the dual space via the potential function, making the update direction better align with the geometric structure.
Convergence Theorem
Theorem 1 (Mirror Descent Convergence):
Let be a -strongly convex mirror map, , convex and -Lipschitz. Choose , then:
Standard Settings
-
Ball Setting: , equivalent to projected gradient descent.
-
Simplex Setting: (negative entropy), Bregman divergence is KL divergence, projection achieved via renormalization.
-
Example: When optimizing probability distributions on the simplex, Mirror Descent naturally handles constraints, preventing Euclidean projection bias.
Stochastic Gradient Descent (SGD)
Problem Formulation
The main problem is defined as minimizing a function , where is the parameter vector. The specific form is:
Here, is typically an expected loss function, expressed as:
-
is a random variable representing a data point (e.g., features and labels).
-
is the unknown distribution, reflecting that in real-world problems the data distribution is often unknown and must be estimated from samples.
-
is the loss function, parameterized by , used to measure the model’s performance on data point .
Core Idea: Learn parameters by minimizing the expected loss, but since is unknown, empirical risk minimization is used in practice, approximating the integral with the sample mean.
Given a set of labeled training data , the goal is to find the weight parameters to classify the data. This connects the optimization problem with supervised learning tasks like classification or regression.
In simple terms, the main problem is to optimize parameters to minimize the model’s average loss over all possible data, but due to the unknown distribution, we rely on finite samples.
Motivation
When the dataset is huge (e.g., ), computing the full gradient becomes impractical. Specific analysis:
Define as the cost function for the -th observation, drawn from a training set of observations.
The full gradient requires iterating over all data points; the computational cost grows linearly with , creating a bottleneck when is very large.
Therefore, cheaper methods can be used: compute the gradient of a single component or a mini-batch gradient. This introduces Stochastic Gradient Descent (SGD) or its variants, which approximate the gradient by randomly sampling a subset of data points, significantly reducing the computational cost per iteration.
SGD Algorithm Description
The basic steps of stochastic gradient descent are as follows:
-
Initialization: Set the initial point .
-
Iteration Process: For each time step :
- Randomly and uniformly sample an index .
- Update parameters: , where is the learning rate.
Here, is called the stochastic gradient; it uses the gradient of only a single function component , not the full gradient .
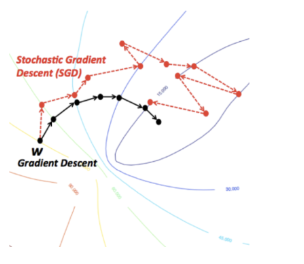
Advantage: Computational Efficiency
- Each iteration computes the gradient of only one function component, so the iteration cost is times lower than Full Gradient Descent.
- This makes SGD more scalable for large datasets.
Convergence Considerations
Although SGD is computationally efficient, using the gradient of a single component does not guarantee convergence. The document provides an example to illustrate this issue:
Example: Consider the optimization problem , where and . If starting from and randomly sampling , the gradient update may cause the function value to increase (because , the update direction might be wrong).
However, SGD can produce descent in expectation, leading to the concept of unbiasedness.
Unbiasedness
The stochastic gradient is an unbiased estimator of the true gradient , i.e.:
where the expectation is taken over the random index .
Significance: Unbiasedness ensures that on average, the update direction of SGD is correct. Although individual steps may randomly deviate, in the long run, the algorithm converges towards the optimal solution. This allows the use of expectation inequalities to analyze convergence, rather than relying on strong assumptions like convexity.
Conditional Expectation
Definition
Conditional expectation is a core concept in probability theory and statistics, used to approximate a random variable given partial information (e.g., the value of another random variable).
-
Definition: Let X and Y be random variables. The conditional expectation of X given Y, denoted , is the best approximation of X using only the information from Y.
- This differs from the unconditional expectation : gives the overall average of X, while gives the average of X given the value of Y.
- Intuitively, conditional expectation “filters out” the influence of Y, providing a more precise local estimate.
Explanation: Conditional expectation is commonly used in machine learning to handle partially observed data, such as optimizing model parameters in stochastic gradient descent.
Properties
-
Linearity: Conditional expectation is linear, i.e., for random variables X and Y, and constants a and b:
The document implies similar properties, e.g., for Z = X + Y or Z = XY, conditional expectation may satisfy addition or multiplication rules, but specific formulas are not given.
-
Partition Theorem: For discrete random variable Y, this theorem provides a simplified method for computing expectations.
- Theorem statement: If Y is a discrete random variable, then the unconditional expectation can be computed via the expectation of the conditional expectation, i.e.:
This means first compute the conditional expectation of X given Y, then take the expectation over Y.
- A footnote in the document indicates that formal definitions and properties can be found in relevant textbooks; this theorem is a special case of the Law of Total Expectation.
- Theorem statement: If Y is a discrete random variable, then the unconditional expectation can be computed via the expectation of the conditional expectation, i.e.:
Example: Suppose Y is discrete (e.g., a categorical variable), then can be obtained by computing for each possible value of Y and taking a weighted average.
Convexity of Expectation
-
For any fixed x, the linearity of conditional expectation allows simplification of calculations:
where f is a convex function.
-
The document mentions that the event occurs only for x in a finite set X (i.e., is determined by the index selections from previous iterations). This implies that in iterative algorithms (like stochastic gradient descent), parameter updates are limited to a finite number of options.
-
Application of the Partition Theorem: By decomposing the expectation into conditional expectations, convexity analysis can be simplified. For example:
where L is the loss function, aiding in convergence proofs.
Explanation: In stochastic optimization, this convexity analysis ensures algorithm stability and convergence even with noisy data.
Summary
The document focuses on the definition and properties of conditional expectation (such as linearity and the Partition Theorem) and its application in convexity analysis. These concepts are fundamental to stochastic optimization and machine learning, helping to handle uncertainty and partial information. Conditional expectation, as a “best approximation” tool, plays a key role in model training and convergence proofs.
Note: Image labels mentioned in the document (such as ``) are not embedded in the summary as the specific content is not provided, and to avoid fabrication. The summary is strictly based on the text content.
Convergence Theorems
Theorem 2 (SGD on Convex Functions):
Let be convex and differentiable, be the global optimum, , and . Choose constant step size , then:
Proof Outline:
-
Basic Inequality: Start from the iteration rule:
-
Take Expectation: Utilize unbiasedness and convexity expectation:
-
Summation and Optimization: Sum from to , and substitute step size :
-
Jensen’s Inequality: Apply to obtain the final bound.
Geometric Interpretation: SGD moves in a descent direction in expectation, but variance causes oscillations; the step size balances convergence speed and stability.
-
Notation: is the initial error bound, is the stochastic gradient norm bound, is the number of iterations.
-
Comparison with GD: The full gradient descent norm bound is usually smaller than SGD’s (due to Jensen’s inequality), but SGD has lower cost per round, resulting in higher overall efficiency.
Theorem 3 (SGD on Strongly Convex Functions):
Let be -strongly convex, be the unique optimum, choose step size , then:
Proof Details (Supplemented from Document2 P26)
Proof Steps:
-
Strong Convexity Inequality:
-
Iteration Analysis: Substitute the SGD update rule, take expectation:
-
Recursive Solution: Set , use the recurrence relation and summation to obtain the convergence bound.
Geometric Interpretation: Strong convexity ensures the function has a unique minimum; SGD converges at a linear rate, but the variance term affects precision.
Mini-batch SGD
Use batch update: , where is a random subset.
-
Notation: is the batch size, is equivalent to SGD, is equivalent to GD.
-
Variance Calculation (Supplemented from Document2 P31):
As , the variance tends to zero.
-
Geometric Interpretation: Batch averaging reduces variance, making the gradient estimate more stable, but increases computational cost per round.
Stochastic Subgradient Descent and Constrained Optimization
For non-smooth problems, use subgradient , update: . For constrained problems, add a projection step (Projected SGD), convergence rate remains .
Momentum Methods
Motivation
GD oscillates severely on long, narrow valley-shaped functions. Momentum methods introduce historical step information to accelerate convergence.
-
Geometric Interpretation: Momentum acts like an inertial ball, accelerating in flat directions and damping in steep directions, reducing oscillations.
Heavy Ball Method (Polyak Momentum)
Update rule:
Or equivalently:
where is the momentum coefficient.
-
Notation: is the momentum term, controls the weight of history.
-
Geometric Interpretation: The momentum term retains the previous direction, helping to traverse locally flat regions.
Convergence
Theorem 4 (Convergence on Quadratic Functions):
Consider the strongly convex quadratic function , where is positive definite, condition number . Choose , , then the heavy ball method converges at a linear rate.
Proof Outline
Proof Idea:
-
Through eigenvalue analysis, the momentum term improves the convergence constant of GD.
-
Detailed proof can be found in Document 1, Page 39, and references (e.g., Wright & Recht, 2022).
Geometric Interpretation: For quadratic functions, momentum adjusts the step size to match the eigenvalue distribution of the Hessian matrix, accelerating convergence.
-
Counterexample (Document 1, Pages 41-44): For a piecewise quadratic function , although it is 1-strongly convex and 25-smooth, the heavy ball method may cycle without converging (e.g., with , , , iterations may cycle among three points).
- Geometric Interpretation: Non-smooth points cause incorrect momentum directions, leading to oscillations.
- Schematic Diagram:
![Potential oscillation diagram description - specific image content not provided]
Nesterov’s Accelerated Gradient Descent
Similar to the heavy ball method but uses a lookahead point to compute the gradient, with more robust theoretical guarantees. Update rule difference:
-
Heavy Ball: Directly combines current gradient and momentum.
-
Nesterov’s Method: First moves along the momentum direction, then computes a gradient correction.
-
Geometric Interpretation: Nesterov’s method reduces oscillation through “lookahead” steps, making it more suitable for general convex functions.